先週、アメリカ・アナハイムで開催された世界最大の楽器の展示会、The NAMM Show 2025。DTMステーションでは、そのNAMM Showレポートの第1弾として、Synthesizer V Studio 2の発表について記事にしたところ、やはり多くの反響をいただきました。その一方で、その場ではあくまでもα版の展示だったこともあり、記事では紹介できていなかったことも多かったのも事実です。
そこで、NAMM会場において、Synthesizer Vの開発者であり、Dreamtonicsの代表取締役でもあるKanru Huaさん、そしてDreamtonicsでプロダクト・スペシャリストであるMiguel Reséndiz(ミゲル・レセンディス)さんにいろいろとお話を伺ったので、インタビューの形で紹介してみましょう。

世界最大の楽器の展示会、The NAMM Show 2025の会場でインタビューに応えてくれたDreamtonicsの代表取締役、Kanru Huaさん
DreamtonicsがSynthesizer V Studio 2について約1時間のビデオで発表
Synthesizer Vの次期バージョン、Synthesizer V Studio 2については「Synthesizer V Studio 2がNAMMで発表。より人間らしく、より表現力豊かに、より高速に。発売は春ごろか?」という記事でも詳しく紹介しているので、ぜひそちらもご覧いただきたいのですが、DreamtonicsとしてもNAMM Showの開幕直前に以下のYouTubeビデオを通じてSynthesizer V Studio 2に関する発表をしていました
1時間弱のビデオで、英語でのプレゼンテーションではありますが、しっかり日本語字幕もあるし、実際の音が入ったデモもいろいろ紹介されているので、ご覧になると、面白いと思います。その中では、KanruさんにMiguelさんが質問するような形で展開していますが、Miguelさんも現在、日本在住のDreamtonics社員。開発者ではなく、プロダクト・スペシャリストとしてSynthesizer VやVocoflexに関する製品説明やデモを行っています。そんなお二人に、お話を聞いてみました。
より人間らしく歌うようになり、処理速度は3倍に
--今回のNAMM Show、ひっきりなしに人が集まっていましたが、反響はいかがですか?
Miguel:本当にずっと人が切れずに忙しかったですね。驚いたのは、初日の朝に発表したビデオを見て、ここに駆け付けたという方が結構いたことです。初日の午前中こそ、人が少なめでしたが、2日目、3日目とどんどん増えてきた印象です。NAMM全体の来場者数は初日が一番多く、だんだん少なくなっていったようですが、ちょうど逆でしたね。もちろん、NAMM会場に来た人が、たまたまDreamtonicsブースに立ち寄るケースも多く、そうした人の場合、当然、Synthesizer Vについてまったく知らないわけですが、そのリアルな歌声を聴いて、みなさん驚いていましたね。またVocoflexに興味を持っていただく方も多く、ずっと質問攻めにあってましたよ。

Dreamtonicsのプロダクト・スペシャリスト、Miguel Reséndizさん
--ここから、Synthesizer V Studio 2(以下Synthesizer V 2について伺っていきます。実際このα版を触ってみると、本当にレスポンスがよくなってますよね。
Miguel:そうですね。300%の速度、つまり3倍のスピードになっています。これはレンダリング時間もそうですし、波形の描画速度も大きく向上しています。さらに歌声データベースの読み込み速度の向上も大きいんです。これまで利用している歌声データベースが増えてくるとだんだん重くなってくるという問題がありましたが、まったくゼロからソフトを作り直したことで、そうした問題もすべて解消され、サクサク動作するようになっています。
処理速度が3倍になったという、Synthesizer V Studio 2
--これまでもSynthesizer V、非常に人間的な歌声でしたが、Synthesizer V 2になって、さらにリアルになってますね。
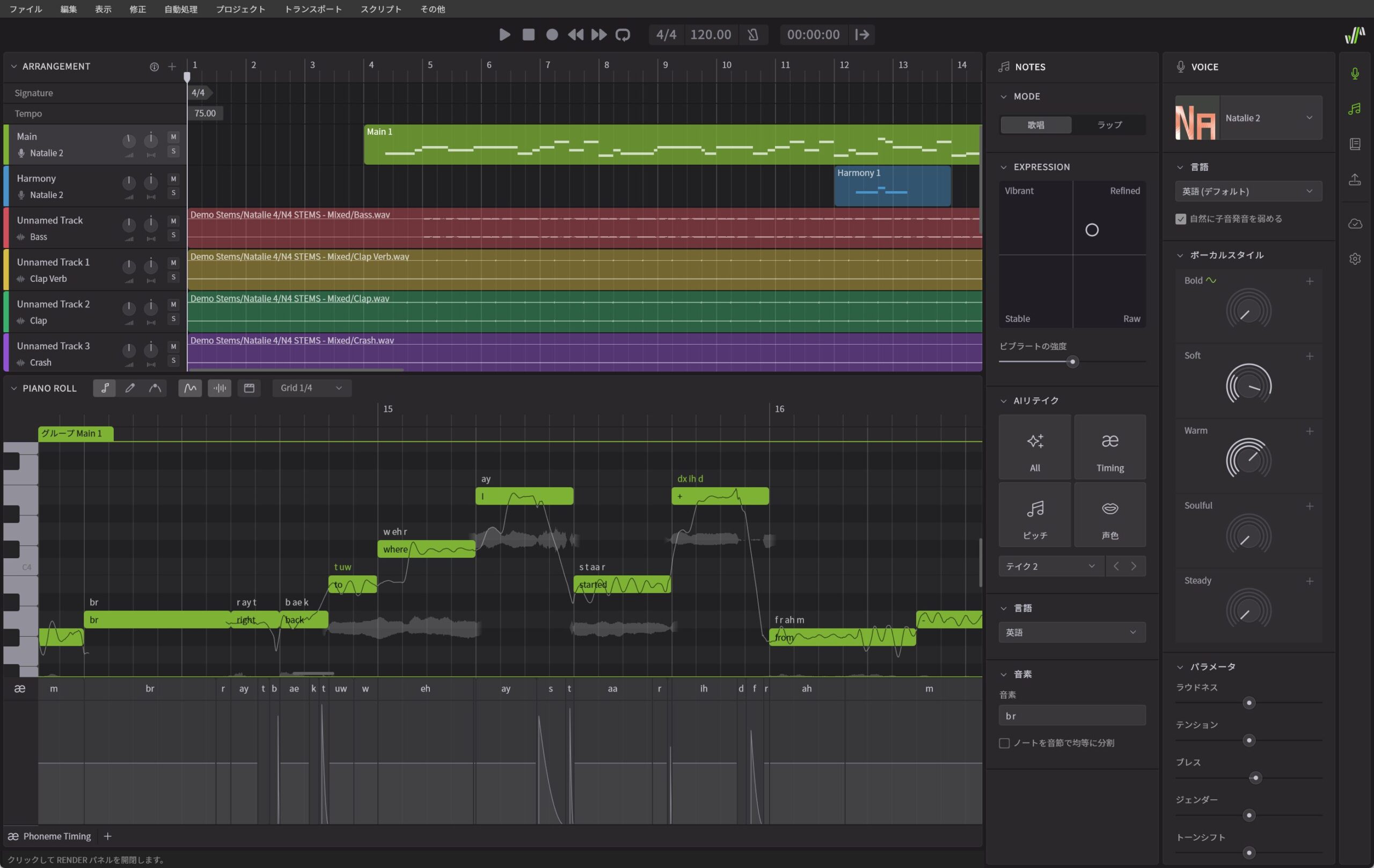
Kanru:はい。もちろん、そこがSynthesizer V 2の最大の特徴です。また単に人間的になっただけでなく、さまざまな進化をさせています。まずはボーカルスタイルというパラメータによって、より大きく歌声の方向性を変えることが可能になりました。たとえばNatalieであればBold、Soft、Warm、Soulful、Steadyと5つのパラメータがありますが、これらを調整することで、デフォルトの状態と比較してまったく違う歌声に仕立てることが可能になっています。
開発中のSynthesizer V Studio 2を使いながら説明してくれるKanruさん
--従来のSynthesizer Vでもボーカルスタイルはありましたよね?
Miguel:はい、従来もありましたし、パラメータも基本的に同じではあるのですが、掛かり方が大きく変わっていて、より変化量が大きくなっているために幅広い歌唱表現が可能になっているのです。また、従来のパラメータはスライダー型だったのがノブ型になるとともに、+ボタンを押すと、Pitch(ピッチ)、Timbre(声色)、Pronun(発音)という3つのパラメータに分解されるようになり、ピッチだけを変えたいとか、声色は一切動かさずに……といった使い方も可能になっています。
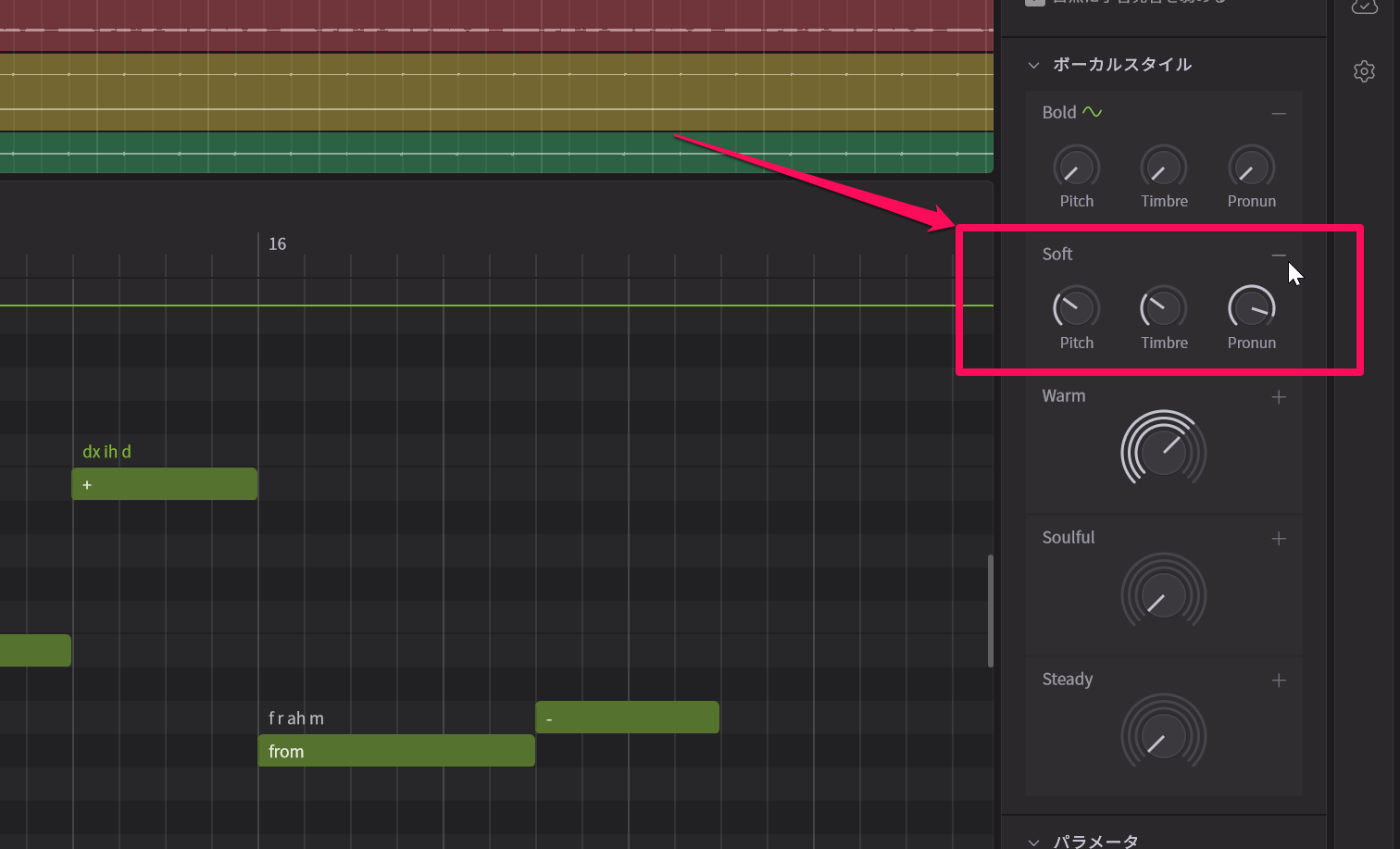
ボーカルスタイルのパラメーターが、さらに3つに分解できるようになっている
--従来のSynthesizer Vだと、歌声データベースによって変更できるボーカルスタイルのパラメータが違いましたよね。その点はSynthesizer V 2でも同様ですか?
Miguel:はい、従来と同様です。やはり歌声データベースによって、向いている歌声の方向が異なるので、パラメータが異なるのです。たとえば力強くクラシックで、豊かなオペラ的な要素を持つFeliciaの場合、MusicalとかOperaticといったパラメータがあるといった具合で、そうした点は、Synthesizer V 2でもそのまま引き継いでいます。

忙しい中、丁寧に解説してくれたMiguelさん
歌い方の表現力に幅を持たせるEXPRESSIONとAIリテイク
--ここでちょっと気になるのは、従来のSynthesizer Vの歌声データベースをそのまま読み込むことができるのか、という点です。
Kanru:そこは、いろいろ構造が異なることもあり、そのまま読み込んで使うことはできません。そのため、Synthesizer V 2用の互換版歌声データベースを我々のほうで作り、それを配布する形になると思います。

NAMMの会期中3日間、常に人が集まっていたDreamtonicsのブース
--さて、そのSynthesizer V 2、なんといってもスゴイのが、EXPRESSIONとAIリテイクの部分ですよね。これについて、少し説明をお願いします。
Kanru:Synthesizer V 1.7でAIリテイクを搭載したことで、実際の人間のボーカリストの歌声をレコーディングするのと同様に、リテイクが可能になり、しかもボタンをクリックするだけで何度でもリテイクが可能になりました。ただ人間のリテイクであれば、ボーカリストに、歌い方の指示を出すわけですが、従来のAIリテイクではそうしたことができませんでした。そこで、今回EXPRESSIONというものを追加したのです。ここではVibrant(活気に満ちた)、Refined(洗練された)、Stable(安定した)、Raw(生)という4つの領域に分けていて、表現の仕方を調整できるようになっています。たとえばStableにすると安定的な歌い方になるので、AIリテイクを重ねても、外れがない歌い方になります。同様にRefinedもStableとは違う方向ではありますが、これを強めにすれば失敗のない上手な歌い方になります。それらに対してRawにしていくと、より自由なピッチ表現になるので、ものすごく上手に歌うこともあれば、酷い歌い方になることもあり、当たり外れがあります。Vibrantも活気に満ちた元気な歌い方にはなるけれど、失敗することもありますね。
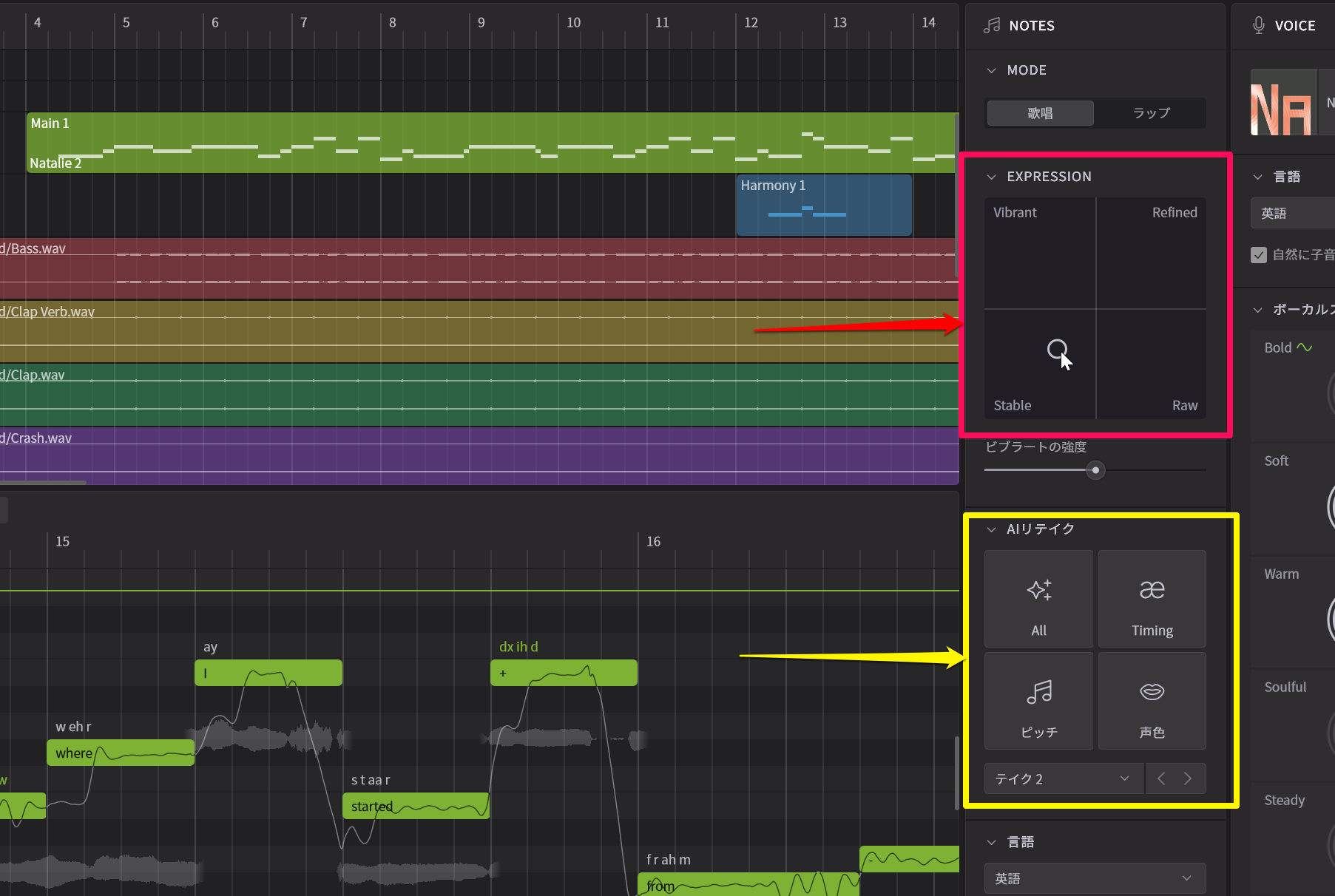
EXPRESSIONで表現の方向を定めた上で、AIリテイクで別のテイクを生成していく
Miguel:この辺をどう使うかはユーザーによって違うとは思います。お勧めの方法としてはメインボーカルはRawやVibrantを使ってリテイクを繰り返しながら、最高なパフォーマンスを見つけつつ、コーラスはStableやRefinedを利用して無難なテイクにしていく方法ですね。こうすることで効率よく、制作することが可能になると思います。

音素の位置や、強さを分かりやすくエディット可能に
--エディットの仕方もいろいろと変わってますよね?
Miguel:そうですね。いろいろと新しい機能がありますが、まずは発音のタイミングの調整が大幅にしやすくなっています。これまでのバージョンだと一つのノートを選び、ノートプロパティの項目を見ると、音素という項目がありました。たとえば、1つのノートに「KEY」という単語が入っていたとしましょう。その場合k、e、cl、yという4つの音素に分解されるとともに、それぞれの長さと強さというパラメータを使ってスライダーで調整する形になっていました。これが分かりにくいというご指摘をいただいていたのも事実です。そこで、ピアノロールの下のパラメータに発音タイミングとして表示させ、音素がセパレータで分かれる形になっているんです。これをドラッグして調整できるようにしました。これにより、視覚的にも、より直感的に、発音タイミングを調整できるようになりました。またタイミングだけではく、強さも調整できるようになっています。
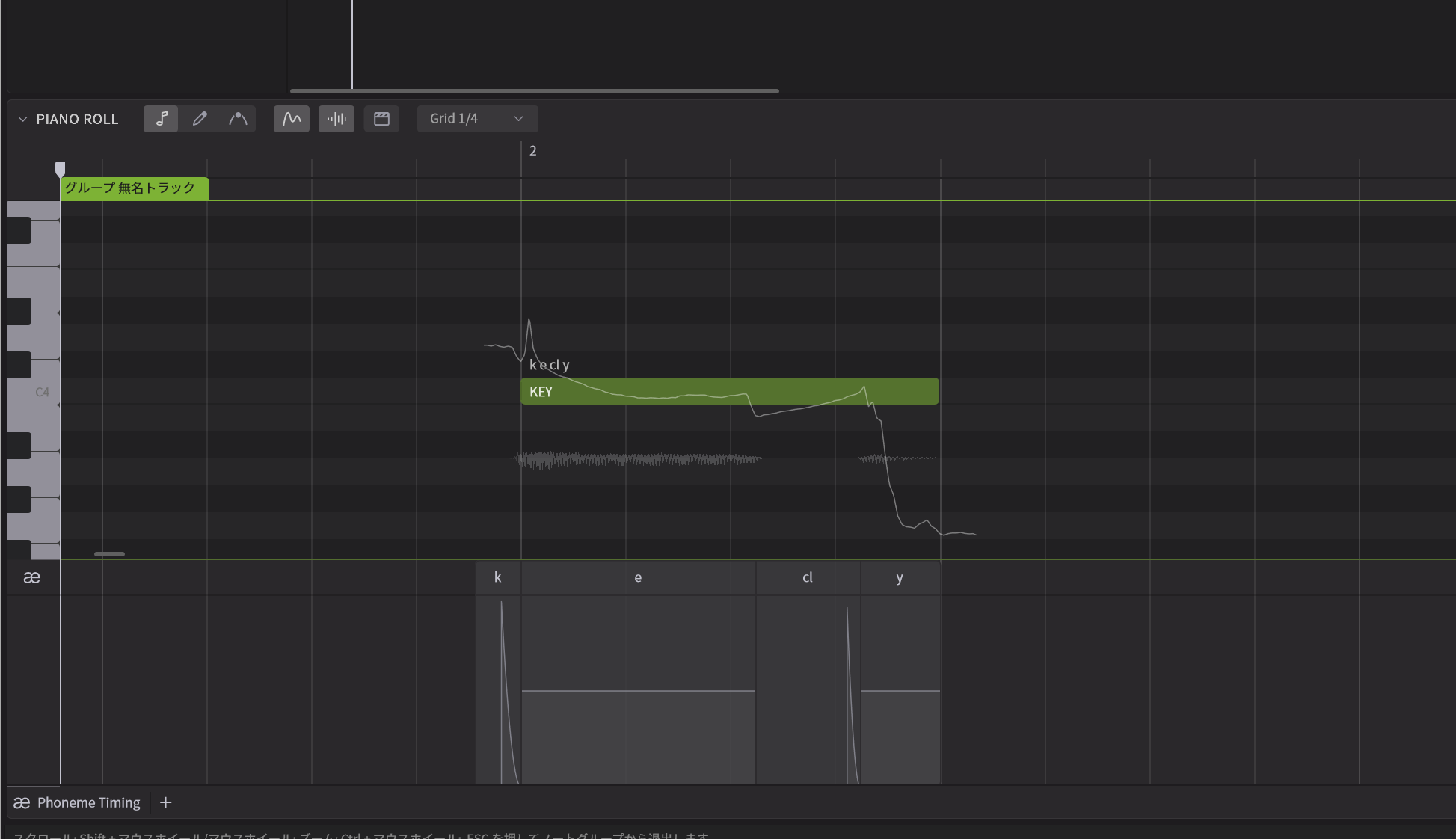
各音素事に分解されて表示され、ここを自由にエディットできる
--これ、見てみると、平坦になっているものと、尖っているものがありますよね。これはどういう意味なんですか?
Kanru:尖っているのはtとかpなど破裂音を意味しています。ここを強くすれば、よりハッキリした発音になる一方、弱くすると柔らかなニュアンスになりますね。また、新たに口の開き方に関するパラメータも追加しました。実は、これまで歌う際に口の開き方がどうなるのか、2年間くらいデータを蓄積してきました。そうした情報を元に、口の開き方と歌い方の関係をリアルに再現するとともに、ユーザーが調整できるようにしたのです。

--ベタ打ちの状態でも口の開き方を変化する形ですか?
Kanru:はい、もちろんです。その上で、「あ~」と歌っているところの口を徐々に閉じていくと少し「う~」とか「お~」に近い感じに変化するなど、歌い方に大きく変わり、結果として大きな表現力が得られるようになりました。
Miguel:そしてもうひとつ、Synthesizer V 2ではスマート・ピッチ・コントロールという画期的な機能を追加しています。
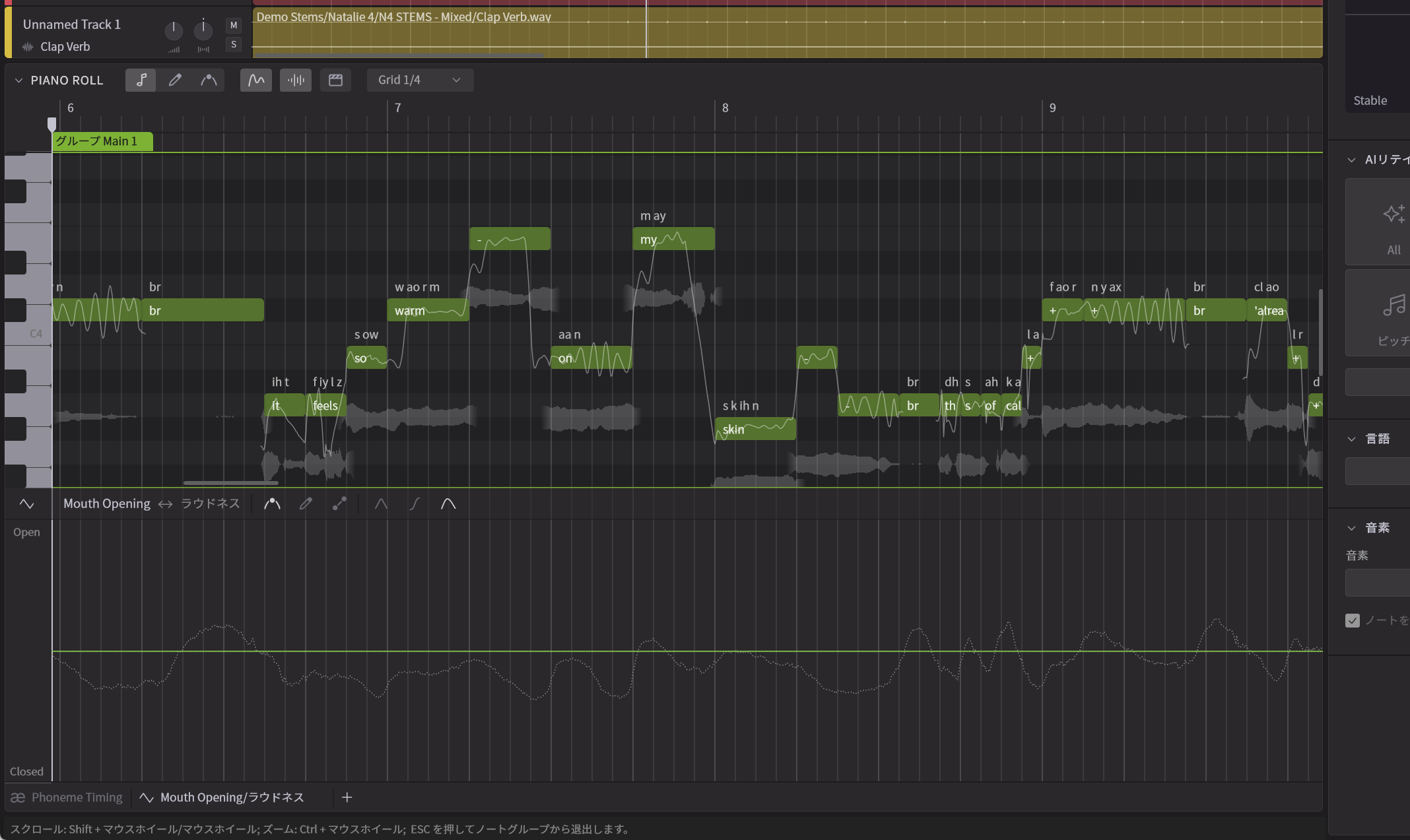
Mouth Openingのパラメータを表示させたところ
ユーザーが何をしたいのかをAIが汲み取って自動調整
--そのスマート・ピッチ・コントロールについて、教えてください。
Kanru:これまでのバージョンでもユーザーがピッチカーブを描くことはできました。しかし、調整したいところだけでなく、その前後のつながりについてもユーザーが上手にピッチカーブを描かないと不自然になってしまう、という問題がありました。そこでSynthesizer V 2では、ユーザーがピンポイントで調整したいところだけピッチカーブを描けば、AIが自然につながるようにしてくれるのです。またピッチカーブをユーザーが描くのではなく、1つポイントを打って、そのポイントを動かすだけで、AIはユーザーが何をしたいと思っているのかを理解し、それに合うように調整してくれるのです。
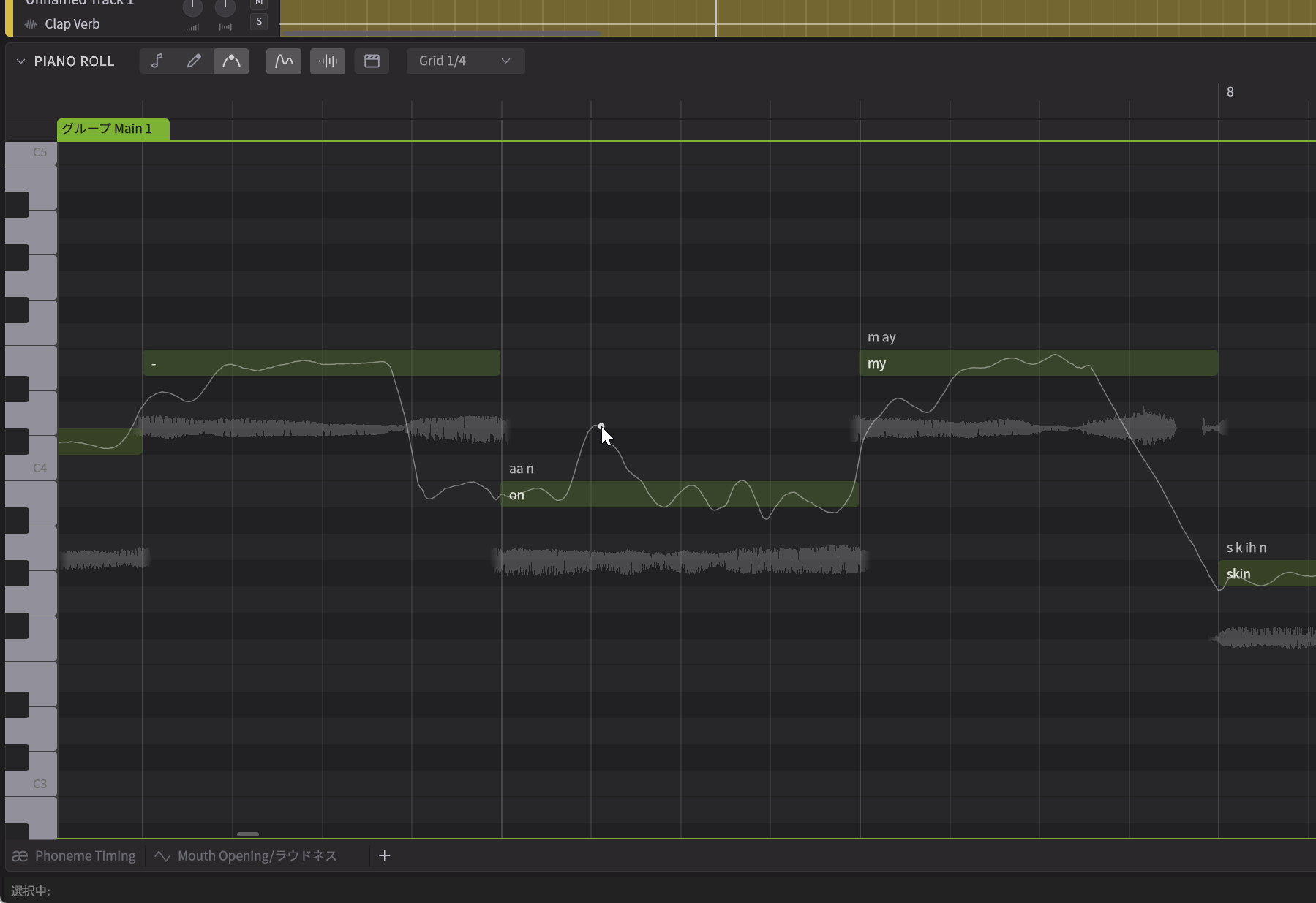
ピッチカーブにポイントを打ってドラッグすると、自然な歌になるように周りの波形が自動的にウニョウニョと変化する
--それは画期的ですね。
Kanru:たとえば、ビブラートの部分に1つポイントを打って調整すれば、ビブラートを深くかけたいのか、よりビブラートの揺れを細かくしたいのかなどを理解し、それに合うように調整してくれる、というわけなのです。そのため、ユーザーは全部を描かなくても、最低限の指定をすればキレイに歌わせることができるのです。
--そのほか、新しい点などありますか?
Miguel:さまざまな新機能、改良点などありますが、ARA2対応において、ProToolsでも使えるようになったのも1つのポイントです。実際、今回のNAMMではAvidのブースにおいてもSynthesizer V 2の展示が行われており、ProToolsの中でシームレスに動作しているのをご覧いただけるようになっています。
NAMMのAvidブースでもSynthesizer V Studio 2が展示・デモされていた
--サードパーティーも、当然Synthesizer V 2に対応していくわけですよね?
Miguel:はい、それはもちろんです。こちらにおいてもNAMMでは当社Dreamtonicsのブースだけでなく、アメリカのパートナー企業であるEclipsed Soundsが出展していて、新製品のデモを行っています。具体的にはHXVOC(ハヴォック)、GALEN

新製品となる歌声データベースをSynthesizer V Studio 2でデモしていたEclipsed Soundsのブース
--最後に、今回のNAMMでユーザーから多く質問があった点などあったら、教えてもらえますか?
Kanru:使い方に関する質問、技術に関する質問などいろいろありましたが、かなり聞かれたのは、この歌声合成の処理をローカルで行っているのか、クラウドで行っているのか、という点です。いまの多くのAIアプリケーションが、クラウドで処理しているので、そこが気になるユーザーが多かったのでしょう。音楽制作は秘匿性が高いケースが多く、発表前に情報が洩れてしまうような事態に起こったら、一大事となります。それに対し、Synthesizer V 2に限らず、現在のバージョンにおいてもすべてローカルで処理を行っており、インターネットには出ていきません。だからこそ、これだけのレスポンスで高速処理もできているわけですが、そのことをお話すると、一様にみなさん、安心してくれるようでした。今後も技術的革新を進めつつ、多くのユーザーに使っていただけるよう開発を進めていきます。
--ありがとうございました。
あのNatalie(ナタリー)の声主、Natalieさんが、Vocoflexのデモを行っていた!
Synthesizer Vのキレイな英語の歌声データベースで知られるNatalie。利用しているユーザーも少なくないと思いますが、このNatalieの声主は、米国で活躍されているシンガーであるNatalieさん。今回のNAMMでは、そのNatalieさんがDreamtonicsブースで、Vocoflexを用いたデモを行っていました。以下がそのときのワンシーンですが、キレイな声で歌いながら、リアルタイムにその歌声を変化させていくというもの。通りかかったNAMMの来場者はその様子に驚いていました。
【関連情報】
Synthesizer V製品情報
Vocoflex製品情報


コメント