アメリカ・カリフォルニア州のアナハイムで世界最大の楽器の展示会、The NAMM Show 2025が1月23日~25日の間、開催されています。ここではさまざまな新製品、新サービスなどが発表されているのですが、DTMステーションとしてまず最初に取り上げるのがDreamtonicsが発表したSynthesizer Vの新バージョン、Synthesizer V Studio 2です。現在のSynthesizer Vが最初にリリースされたのは2020年7月。そこから約4年半、革命的ともいえるバージョンアップを繰り返し、現時点では1.11.2というバージョンまでアップデートしてきたわけですが、ここに来て、抜本的に開発しなおした新バージョン、Synthesizer V Studio 2(以下Synthesizer V 2)が発表されたのです。
現時点では、まだ参考出品という段階で、発売時期や価格などの情報は出ていませんが、NAMMの会場では、その開発バージョンが展示、デモされていました。UIもエンジンも大きくブラッシュアップされており、Dreamtonicsによると新エンジンによって、さらに人間らしい歌い方、よりダイナミックスレンジも広がって、表現豊かになっている、とのこと。また、現行のSynthesizer Vと比較するとレンダリングエンジンの処理速度は300%に向上しており、まったくストレスのない操作が可能になっているのです。一方で、編集を手助けするためのAI機能もいろいろ搭載され、ユーザーが歌わせたいイメージをより簡単に実現できるようになっているのです。まずはそのSynthesizer V 2に関する第一報ということで、これがどんなものなのか、その概要について紹介していきましょう。
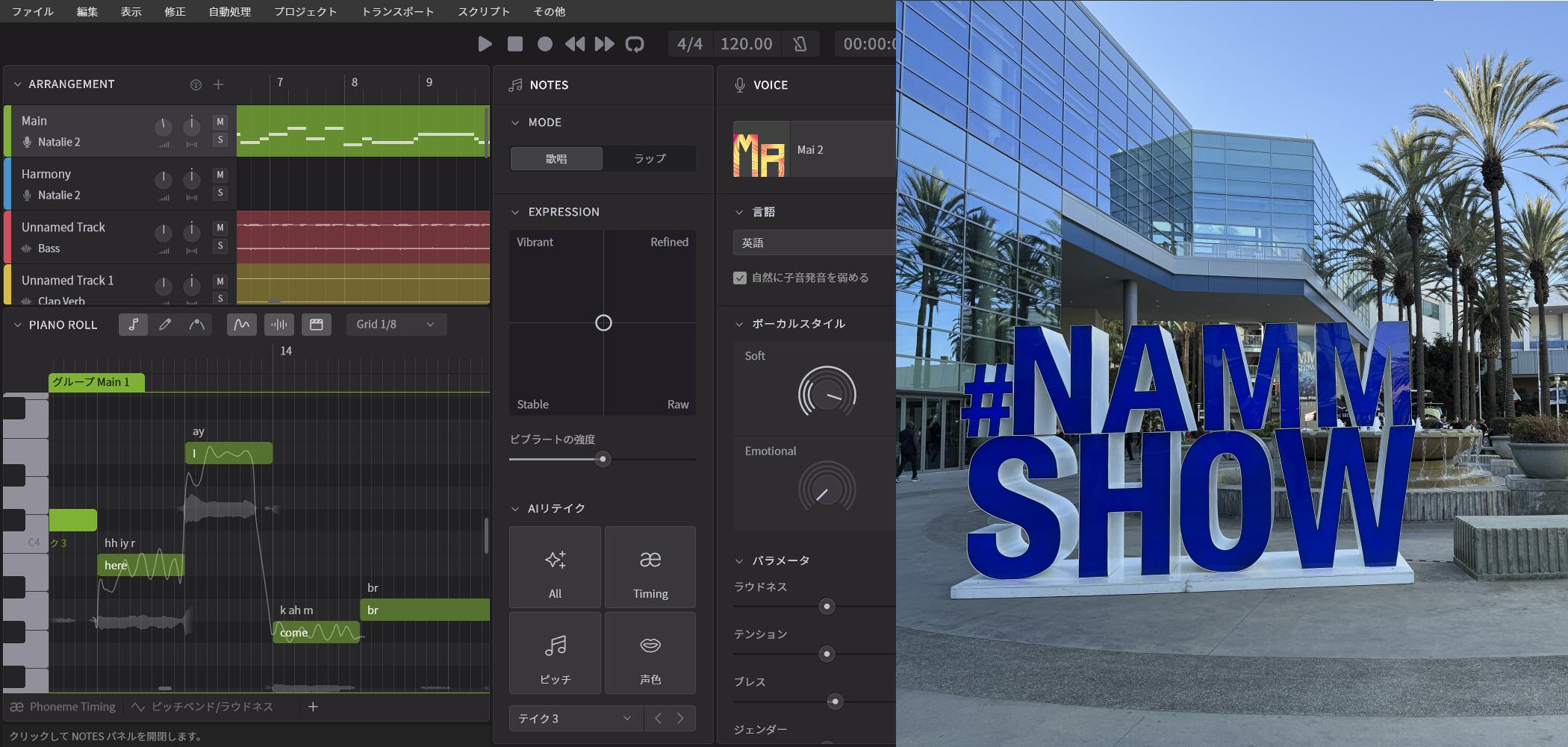
NAMM ShowにおいてSynthesizer V2が発表された
最新のAI歌声合成ソフトウェアとして、新たに作り直したSynthesizer V Studio 2
DTMステーションでは、2020年7月のSynthesizer Vの世界同時発売のだいぶ以前、まだDreamtonicsという会社ができる以前から、その動向を記事にしてきました。その最初は「VOCALOIDの競合となるのか?中国人天才少年が開発した歌声合成ソフト、Synthesizer Vの破壊力」という2018年でした。その後、「歌声合成はさらに次の時代へ。Synthesizer Vがサンプルベースと人工知能のハイブリッドで大きく進化」という記事で、現在のSynthesizer Vの初期バージョンについて紹介し、発売となっていき、歌声合成の世界を大きく変えていったことはみなさんご存じのとおりです。

2025年1月23日~25日で開催されている世界最大の楽器展示会、The NAMM Show 2025
もっとも、この最初のバージョンはサンプルベースのエンジンであり、今のような人の歌声と区別が付かないほどリアルなもの、というわけではありませんでした。その後、アップデートを重ねる中で、Synthesizer V AIという名前とともに、AIを使った歌声合成を実現し、どんどん機能、性能を向上させていったわけです。
われわれユーザーとしては、どんどん進化し、使いやすく、高性能になっていって、嬉しかったわけですが、開発サイドからすると、かなり無理がでてきていたようなのです。ある意味、初期バージョンとはまったく違うソフトといってもいいほどに進化をしていったため、ソフトウェアの構造としては後方互換性も保ちながら、建て増し、建て増しとなっていき、限界となっていたみたいですね。
NAMMに初めて単独出展したDreamtonicsのブースでSynthesizer V Studio 2のデモが行われていた
そうした中、今回、突然ともいえる感じでDreamtonicsからNAMMの会場で新バージョンが発表されたのです。
より人らしく歌うように進化したSynthesizer V Studio 2
このNAMMのDreamtonicsブースでは、Synthesizer V Studio 2 Proのα版が展示、デモされていたのですが、その起動画面を見ると、マイナーチェンジなのかな……という雰囲気です。ちなみにここで載せている画面は、あくまでも暫定な日本語であり、参考までという感じで見てくださいね。
Synthesizer V Studio 2 Proを起動後、トラック画面でワンクリックしてテンポ、拍子を表示したところ
もちろん基本的な使い方は、これまでのSynthesizer Vを踏襲しているものの、画面を開いていくと、随所にさまざまな違いが出てくるのです。まずは、ここでSynthesizer V 2での歌声をちょっと聴いてみてください。
いかがでしょうか?これがNAMM会場で行われていたデモの一つであり、英語なので、そのニュアンスの違いが見えにくいかもしれませんが、かなりリアルであることは十分に感じられるはずです。歌声は、英語シンガーであるNatalieの新バージョンとなるNatalie 2です。
これまでSynthesizer Vを使ってきた方であれば、この動画を見ただけでも、「え?これは何?」、「あ、こっちのは何?」と気になったと思いますが、具体的な新機能や現行バージョンとの違いなどについて、見ていきましょう。
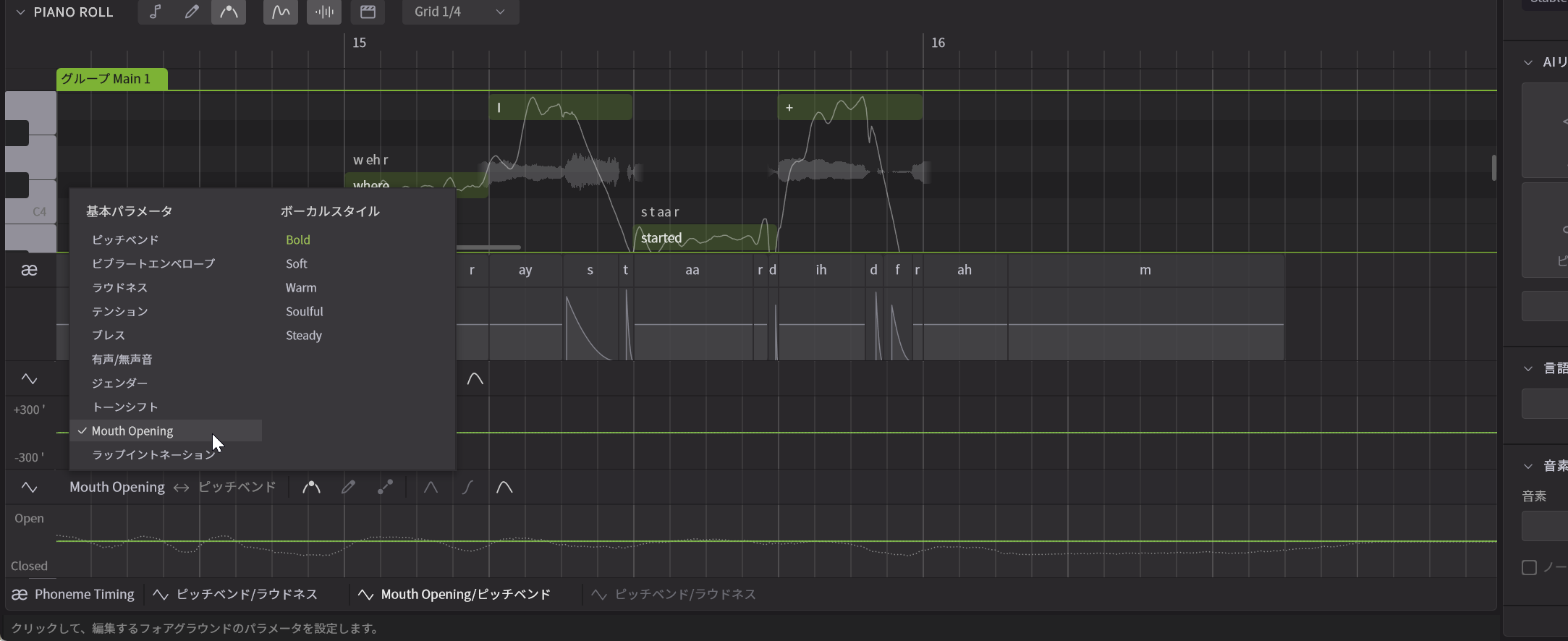
ボーカルスタイルでより好みの歌い方、歌声に
さまざまな新機能がありますが、まず最初に紹介するのは歌声におけるVOICEパネル(歌声パネル)を開いた際に出てくるボーカルスタイル(英語版ではVOCAL MODE)について。これまでも各歌声データベースごとに、ボーカルスタイルというパラメータがあり、これを調整することで、歌声や歌い方が大きく変化していました。たとえばNatalieであればBold、Soft、Warm、Soulful、Steadyといったパラメータがあり、MaiであればSoft、Emotionalというものがあったという感じです。
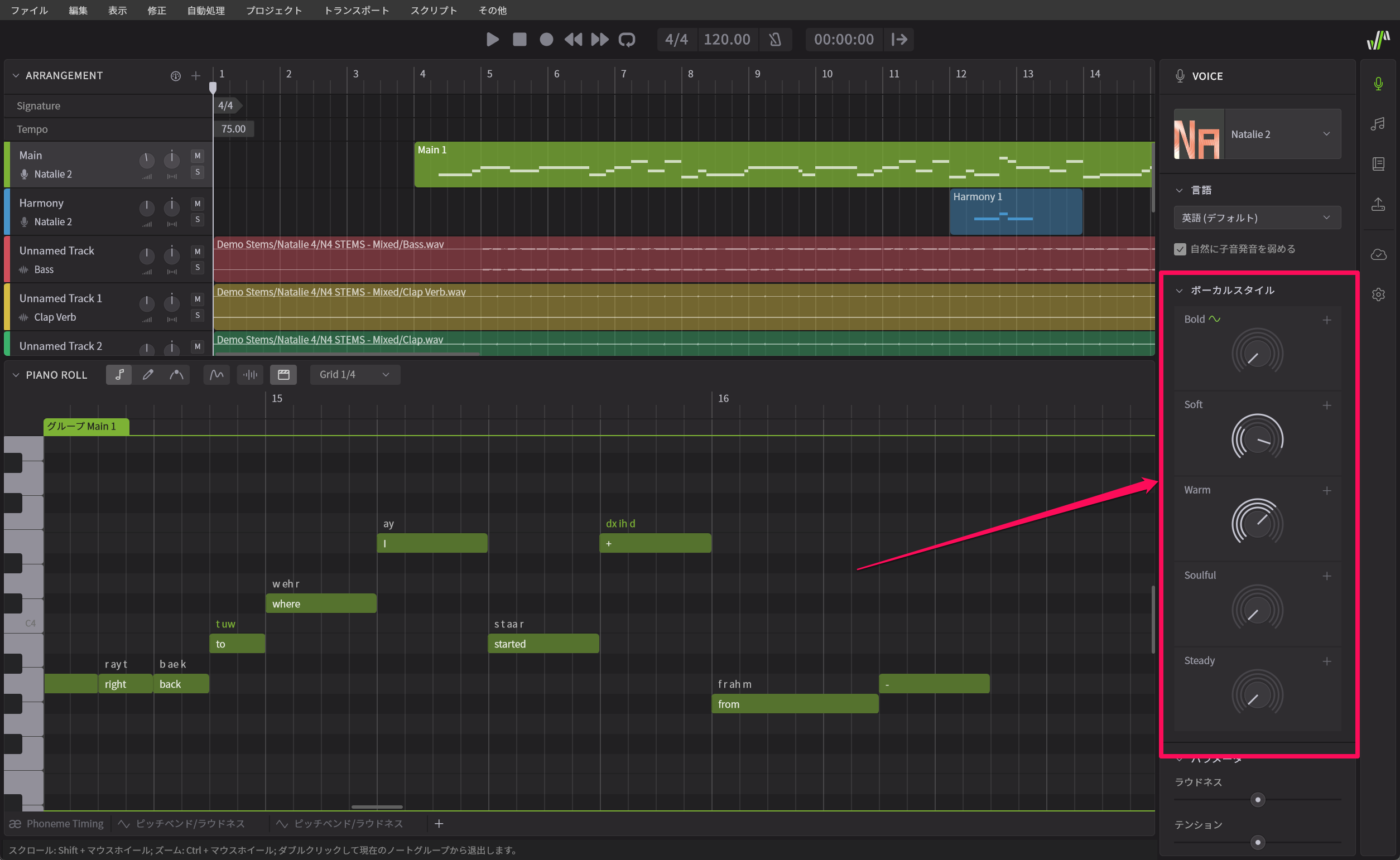
VOICE(歌声)パネルにはボーカルスタイルというパラメータがあり、複数のノブが並んでいる
従来それがスライダー式のパラメータ調整となっていたのが、Synthesizer V 2でノブ型に変化しました。まあ、それだけなら「なんだ、UIだけの話か」と思われるところですが、これを動かしてみると、まずより変化具合が大きくなり、バリエーション豊富な歌い方をするようになり、これまでよりもさらに幅広い表現が可能になっています。
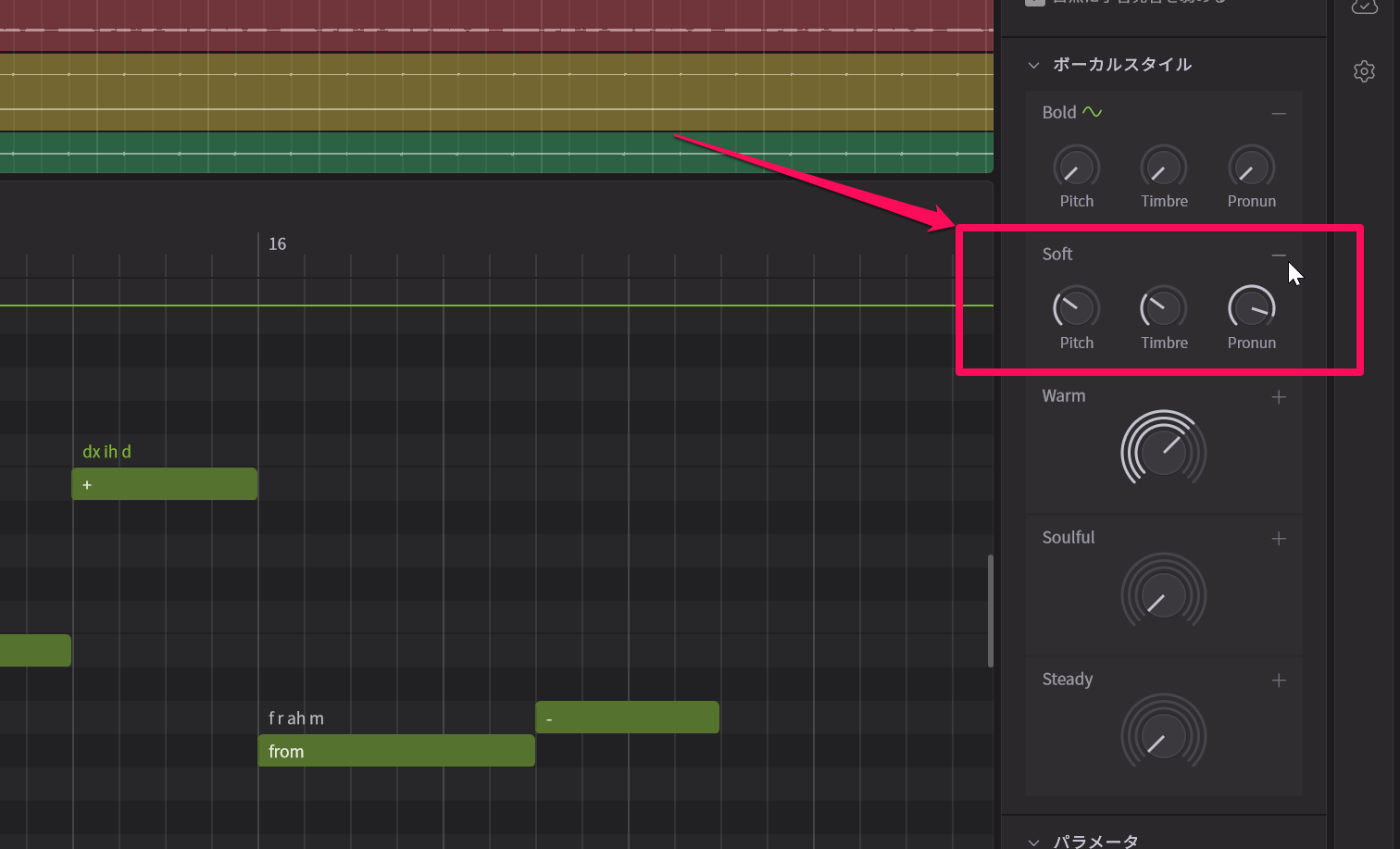
ボーカルスタイルの各パラメータの右にある+ボタンをクリックすると3つのノブに分解される
気になるのが各パラメータの右上にある+ボタン。そうこれを押すと、それぞれPitch(ピッチ)、Timbre(声色)、Pronun(発音)という3つのパラメータに分解されるようになります。つまり、ピッチや発音はいじらずに声色だけ変化させたい、声色はそのままに、ピッチを変化させたい……といったことが可能になり、そのバランスも調整できるのです。これにより、自分のイメージする歌い方に近づけることができるわけです。
AIリテイク機能が大きく進化し、より自分の求める方向へ
現行のSynthesizer Vが進化する過程で、AIリテイク機能が搭載され、まるで本当の人間のレコーディングのようにリテイクをして、しかもボタン一つでどんどん異なるリテイクが可能になったのは以前にも紹介したとおりです。今回のSynthesizer V 2では、そのAIリテイク機能が大きな進化を遂げているのです。
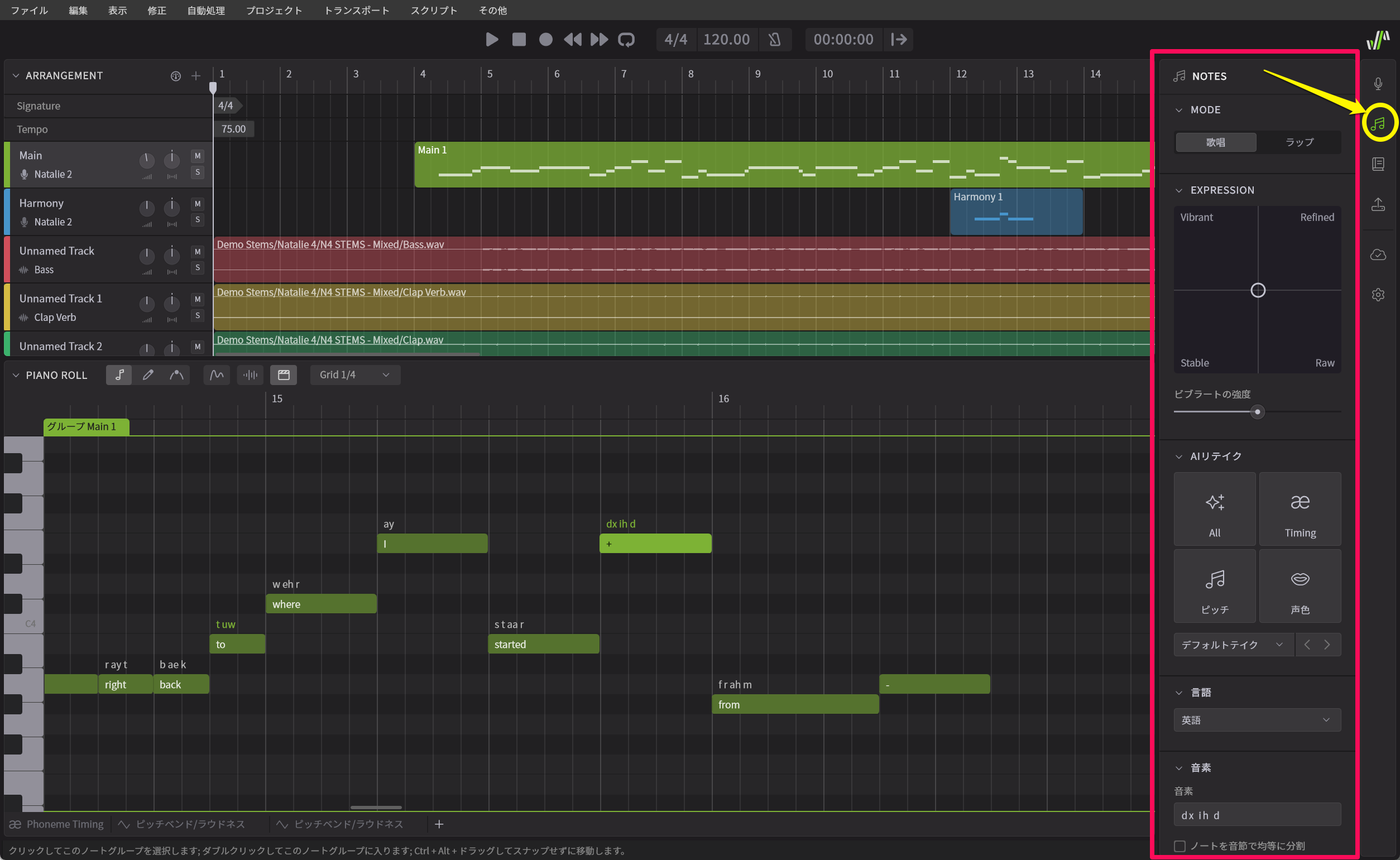
画面右の音符のアイコンをクリックするとNOTES(音符)パネルが開く
まず画面右のアイコンを見ると、AIリテイクがなくなっており、ノートプロパティと合体したNOTESというパネルなっています。上から見ていくと、まずMODEにおいて歌唱モードとラップモードの切り替えが可能となっています。
そしてその下のEXPRESSIONというのが、ある意味Synthesizer V 2の最大の進化点ともいえるところ。二次元のXYパッドのようにも見えますが、会場にいたSynthesizer Vの開発者であり、Dreamtonicsの代表取締役であるKanru Huaさんに伺ったところ、内部的には3次元になっているのだとか……。パラメータとして左上がVibrant(活気に満ちた)、右上がRefined(洗練された)、左下がStable(安定した)、右下がRaw(生)となっており、どちらに寄せるかによって、歌い方が変化するのです。

Synthesizer Vの開発者でありDreamtonicsの代表取締役であるKanru Huaさん
たとえばStableやRefinedだと、外れのない無難な歌い方になるけれど、Rawにすると、より自由なピッチ表現になる一方で、目的とする歌い方とはかけ離れた歌い方になる可能性もあるじゃじゃ馬。。Vibrantも元気にはなるけど、とんでもない歌い方になってしまう可能性も高いのだとか。その下のビブラートの深度では、まさにビブラートの深さを調整していきます。
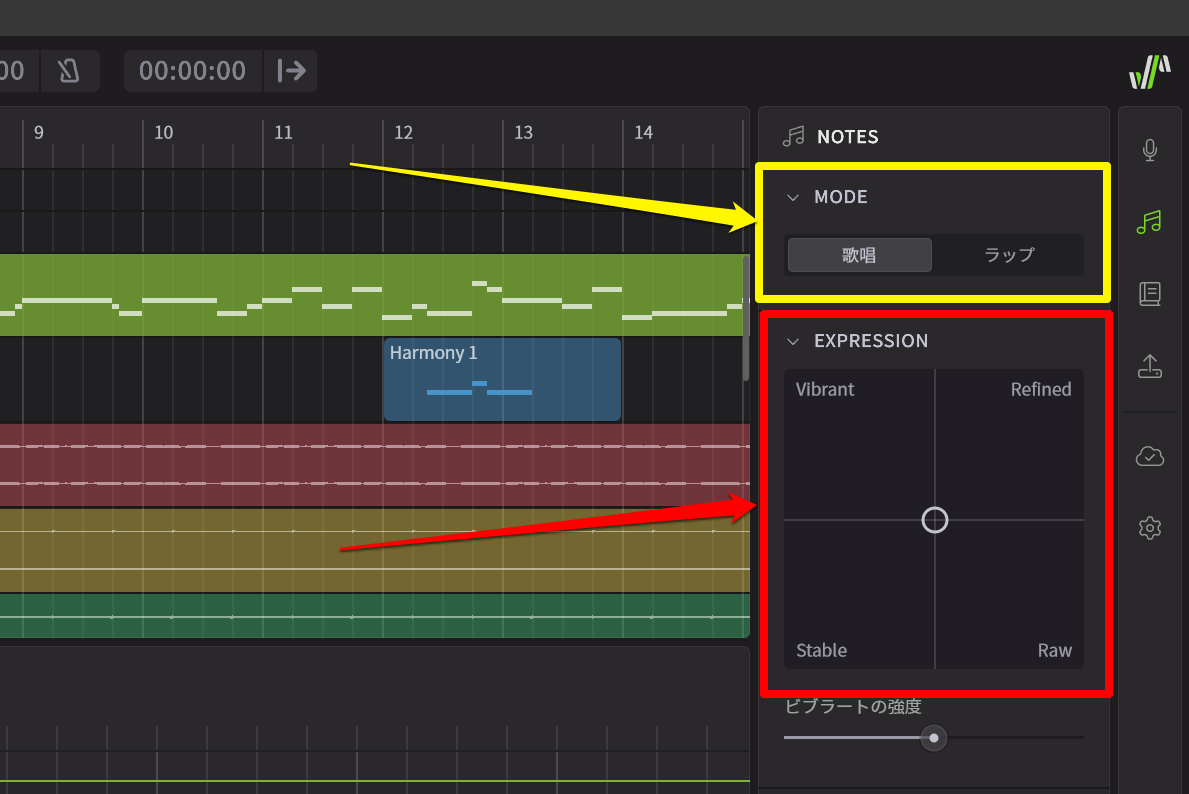
MODEで歌唱かラップ化を選択。その下のEXPRESSIONで歌い方の方向性を調整する
さらにその下にAIリテイクがあるわけですが、この画面を見ても分かる通りTiming(タイミング)、ピッチ、声色そしてAll(全部)の4つのボタンに分かれています。これまでのSynthesizer V でもピッチと声色でAIリテイクすることができたわけですが、今回タイミングも加わり、それらをすべて同時にAIリテイクしたり、一つだけに絞ってリテイクすることができるのです。
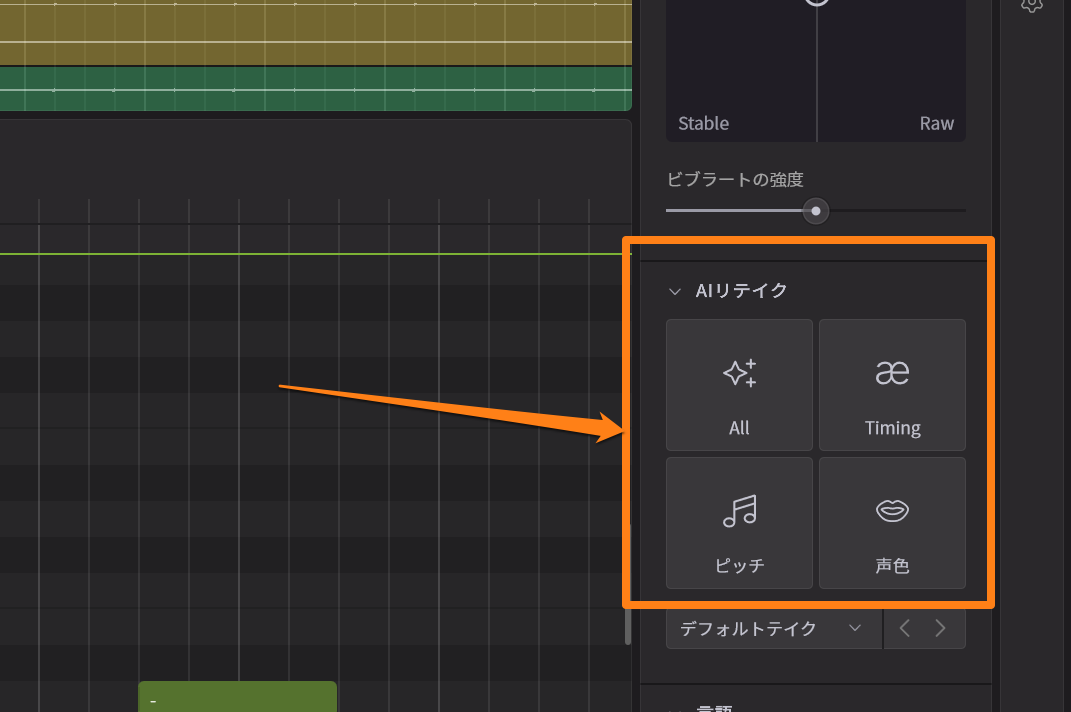
新しくなったAIリテイク。4つのボタンでリテイクできる
しかも、このAIリテイクをする際に、先ほどのEXPRESSIONの設定が効いてくるのです。StableでAIリテイクすれば、無難にいいものができるけど、Rawだと大当たりもあれば、大外れもある、という感じ。この辺は状況に応じていろいろと試してみるのがよさそうです。
AIアシスト機能で、飛躍的に使いやすくなった編集機能
ところで、このSynthesizer V 2に触れてみて、最初に戸惑ったのがノートの入力方法です。これまではペンツールを持ってピアノロール上でドラッグすることで入力できたのですが、今回そのピアノロールのツールバーのアイコンが少し変化するとともに、入力方法、エディット方法がだいぶ進化しているのです。
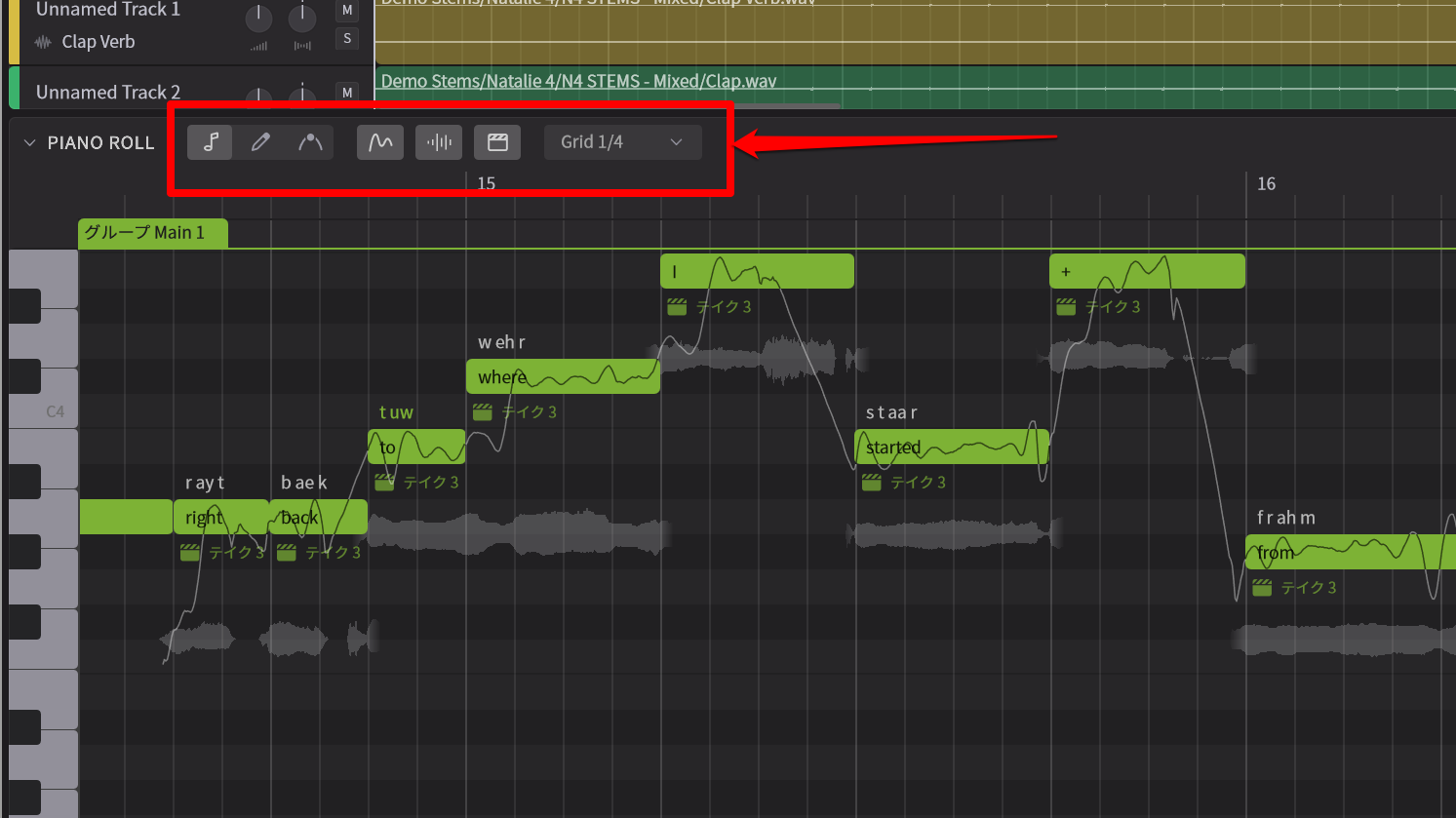
ピアノロールのツールバーの内容が変わり、編集方法も大きく進化している
まずノートを入力する際には音符ツールを選んだうえで、ピアノロール上でダブルクリックとなっているのです。ではペンツールを選ぶとどうなるのか?実はこれがピッチの軌跡をエディットするためのものとなっているのです。「あれ、今までだって、『エンジン処理前のピッチカーブ』、『エンジン処理後のピッチカーブ』というので調整できたじゃないか」と思う方もいるでしょう。これが、大きく変わってるんですよ。

ペンツールを選び、気になる部分だけピッチカーブを描くと周りがのピッチの動きが自動的に自然になるように調整される
このカーブでしゃくるとか、フォールダウンさせるとか、表現を手で描いていったわけですが、それを自然に歌わせるためには前後含めて、いろいろ調整が必要で、そこがSynthesizer V の歌わせ方テクニックの一つでした。
ところが、今回のSynthesizer V 2では、「ここでピッチを下から上え持ち上げたい」などと、指定すると、そこが自然になるように、周りを自動的に調整してくれるのです。ちょっとこれは驚きのアシスト機能でした。
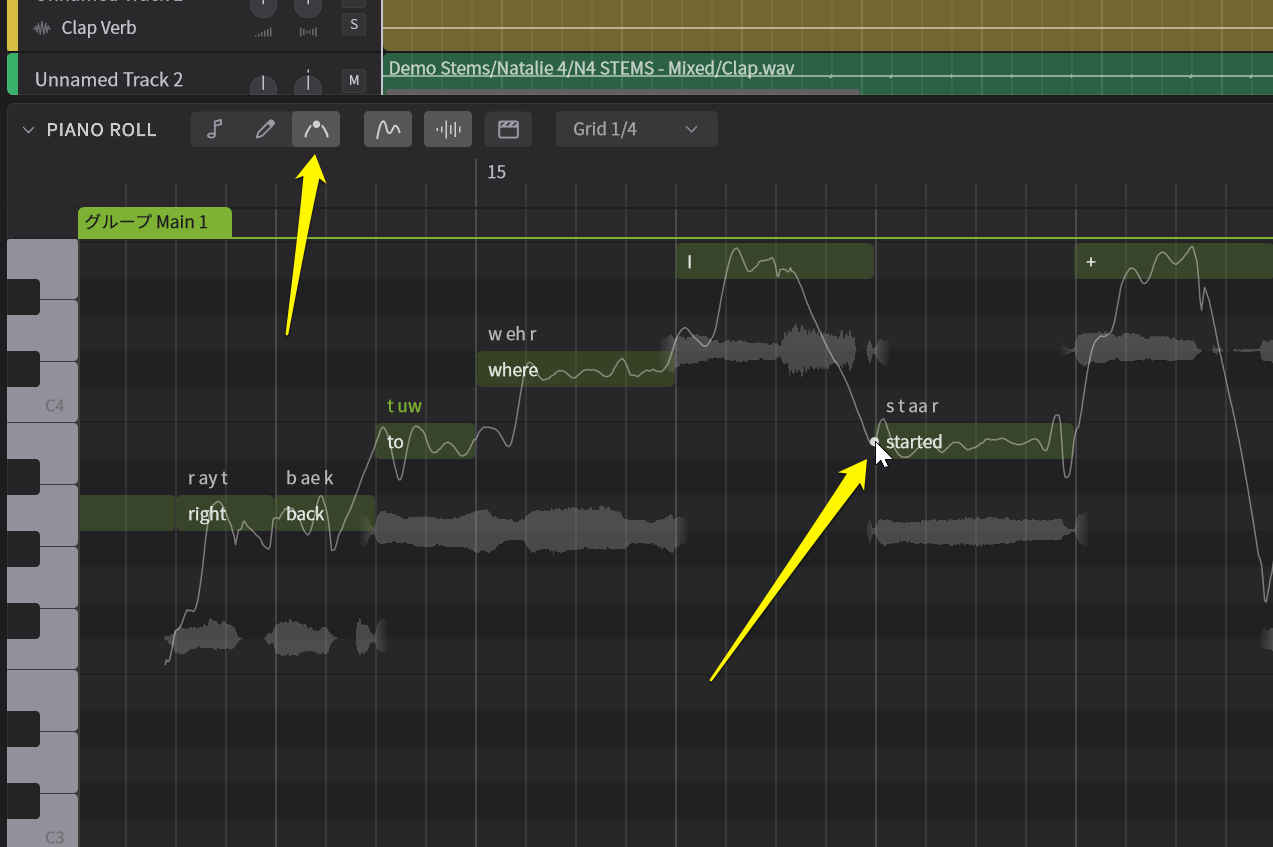
こちらのツールを選び、ピッチカーブをクリックすると点が現れるので、それをドラッグして動かすと周りも自動的に変化する
またペンツールの右には、山形の上に点が付いたようなアイコンとなっていますが、これはピッチの波形を1つつまんで、マウスでドラッグすると、それに合わせて回りの波形もウニョウニョと動いて、いい感じにしてくれるのです。これを従来の方法でやっていたら、非常に大変だったし、まさに職人芸。その描き方次第では、自然さを失っていたわけですが、これなら思い通りに調整することが可能です。
発音タイミングの調整もよりしやすくなった
その編集機能でもう一つ大きく変わったのが、ピアノロールの下に開くパラメータとしてPhoneme Timing(発音タイミング)というものが追加されたこという点。
これを開いてみると、あまり見慣れない画面がでてきますが、上を見ると発音記号が表示されています。また波形的には平のものと、上に突き出たとんがったものがありますが、ザックリいうと、平らなのが母音、とんがっているのが子音ですね。
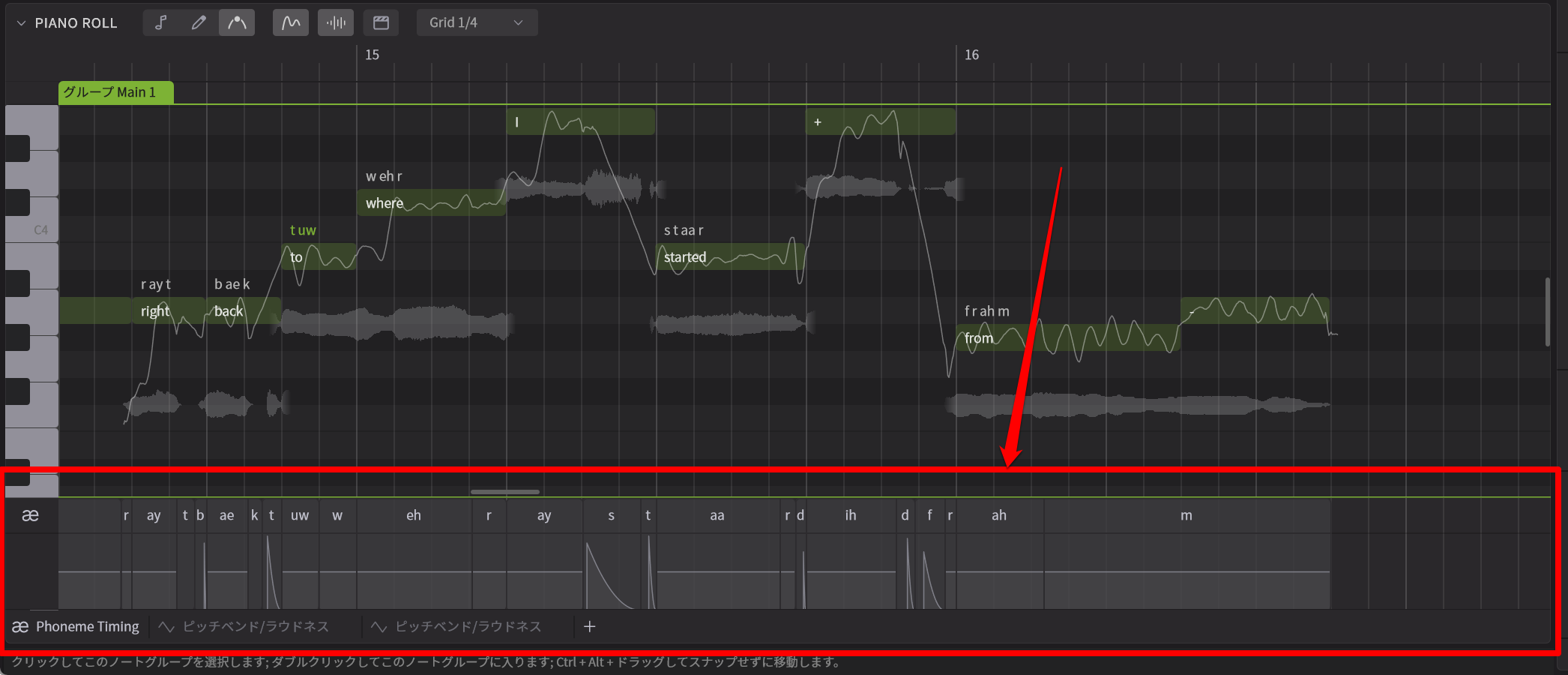
発音タイミングに関するエディット画面が新たに追加された
そしてノートのタイミングとは完全に独立した形で、各母音、子音の発音タイミングを自在に調整できるのです。これにより、ちょっと突っ込んだ歌い方とか、ちょっと後ノリの歌い方にするといったこともできるし、1つのノートで複数の文字を入れ込んだ場合のタイミング調整なんかも思い通りにできるわけです。この際、ノート側はいじらずに、発音タイミングだけを調整できるのも便利なところです。
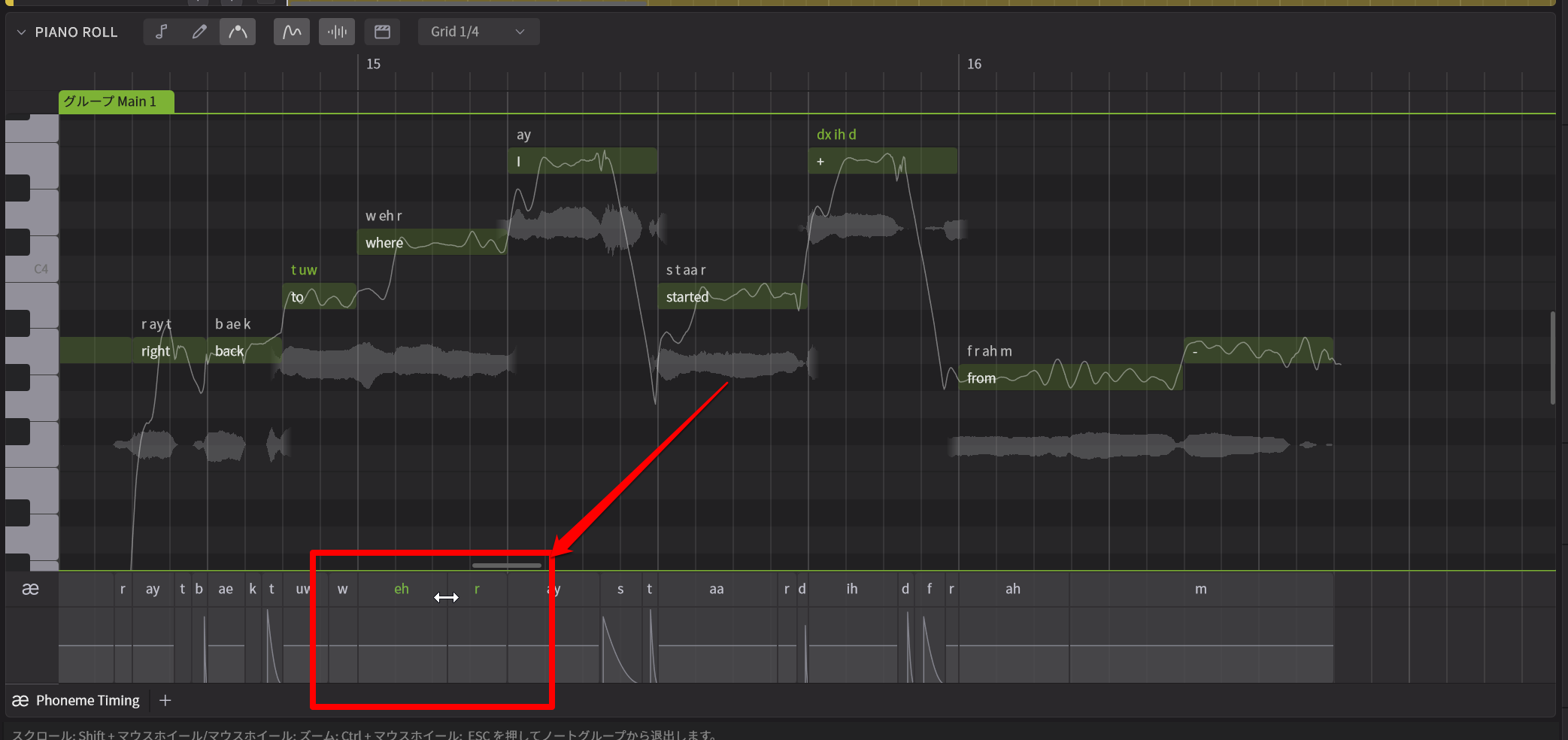
各音素の位置を簡単に調整できるようになった
また子音のとんがり方を調整することで、「S」の「ス」とか「サ」といった歯擦音を強めに出すとか、だいぶ抑え目にするなどの表現の調整も可能。
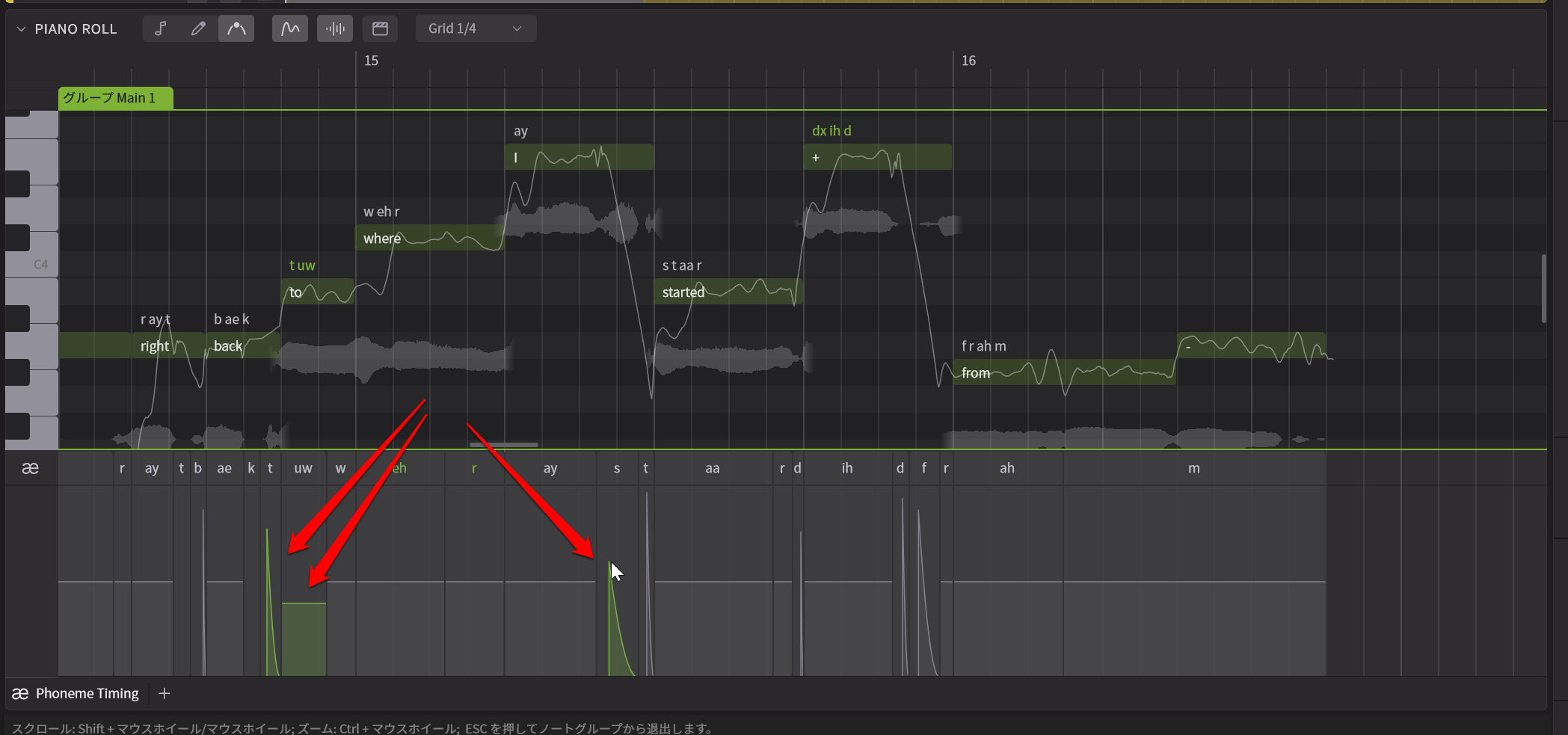
各子音や母音の強さも簡単に調整可能
つまり、AIが自動でアシストしてくれる一方で、より細かな調整を人が行っていくことも、しやすくなっているのですね。そのほかにも口の開き方を調整するためのMouth Openingというパラメータも追加されていました。
mouthopeningという口の開き方を調整するパラメータも追加された
3倍の処理速度になり、ノートPCでもサクサク動作
会場にいたKanru Huaさんがもう一つ強調していたのは処理速度の高速化です。実際見てみると、先ほどの波形編集や発音タイミングの編集を行うと、ほぼリアルタイムで、新たな波形が表示され、すぐに歌わせることができるのです。
今回、まったく新たにソフトウェアを作り直したことで、処理速度が大きく向上するとともに、新エンジンの性能UPも併せて、処理速度が300%に向上しているのだとか。これによって、確かにまったくストレスなく歌わせることができるようになっているのです。また軽くなった分、ノートPCなど低いスペックのマシンでもよりサクサクと動かすことができるようになっていました。

NAMM ShowでのDreamtonicsブース。Kanruさんと左はSynthesizer Vの販売元であるAHS会長の尾形友秀さん
以上、NAMMの会場で見た情報を、凝縮させる形で紹介してみましたが、おそらくほかにも多くの新機能や性能アップというものが図られているようです。この辺については、改めてKanru Huaさんを掴まえてインタビューを行う予定なので、もうしばらくお待ちください。
なお、NAMMのオープン直前に会場から英語ではありますが、YouTube Liveでの製品発表が行われているので、そちらも参考にしてみてください。
【製品情報】
DreamtonicsのYouTube公式ページでのSynthesizer V Studio 2の発表生配信
Dreamtonicsサイト


コメント