いま最先端を行くAI歌声合成ソフトのSynthesizer VやAI音声合成ソフトのVOICEPEAKなどを手掛けるDreamtonicsが、また新たな画期的なシステム、Vocoflexなるものを発表されるとともに、そのベータ版が公開されました。これは人の歌声を10秒程度録音して、その場でAIに学習させると、誰でもその歌声にリアルタイム変換できるというユニークなシステム。WindowsやMacの環境で動かすことができ、マイクに向かって歌えばその場で変換するし、VST/AUのプラグインとしてDAWに挿せば、ボーカルトラックをその学習した人の歌声に変換することができるという、驚くべきソフトです。
単にその10秒程度録音した人の歌声に変換できるだけでなく、AIが歌声を学習し、分析した結果を独特な手法でグラフィック化するUIを採用しているのもユニークな点。その結果、人の歌声の特徴をグラフィックで表現できるとともに、マウスで指定するだけで、学習した複数の人の歌声をリアルタイムに切り替え、さらにはその中間的な歌声を表現することも可能となっています。逆にグラフィックを元に人工的に新たな歌声を作り出すことができるなど、かなりドラスティックなシステムにもなっています。そのVocoflexとは何なのか、どのように使うもので、どんなシステムになっているのかなど、開発者であるDreamtonicsの代表取締役であるカンル・フア(@khuasw)さんに話を伺ってみました。
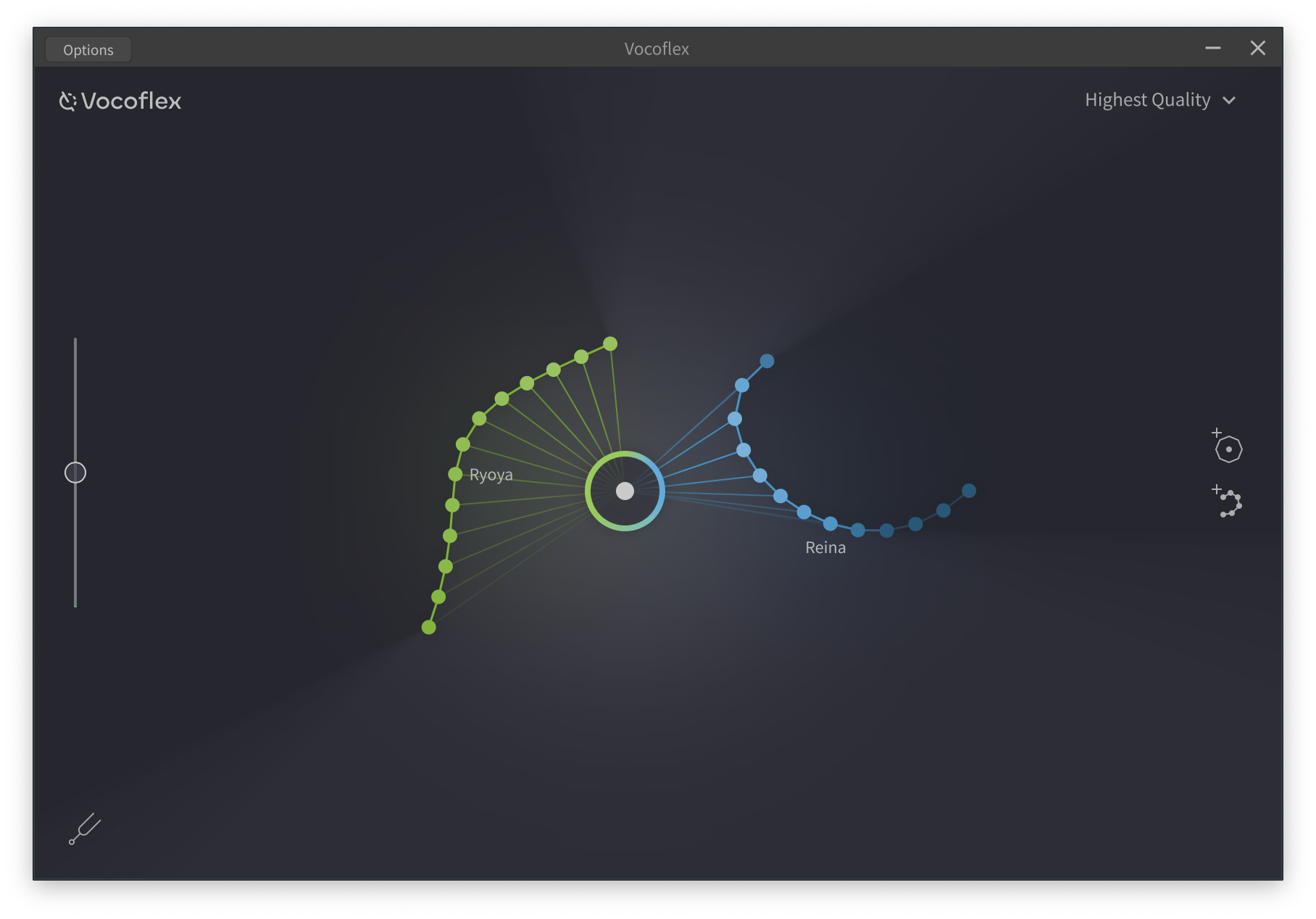 人の歌声を取り込むとその人の声でリアルタイムに歌うことができるボーカルチャンジャー、Vocoflex
人の歌声を取り込むとその人の声でリアルタイムに歌うことができるボーカルチャンジャー、Vocoflex
学習した人の歌声にリアルタイムに変換できるVocoflex
本日4月16日、緊急生配信ということでDTMステーションPlus!の番組において、このVocoflexについて紹介しましたが、これでどんなことができるのか、以下のビデオを見ると、その概要はすぐにつかめると思います。
簡単に説明すると、このVocoflexはWindows、Macの環境においてスタンドアロンでもプラグインとしても動作するソフトです。Vocoflexを利用するには、まず、ターゲットとなる人の歌声を10秒程度録音します。これはマイクから直接録音してもいいですし、すでにあるWAVやAIFF、FLACやMP3…などの歌声のオーディオデータを読み込む形でもOKです。
読み込むと即、学習、分析され、複数の点でつながった線が画面上に表示されます。この線のどこかをマウスで指定した上で、マイクから歌うと、自分の歌声が、学習した人の歌声にリアルタイムに変換されてしまうのです。設定にもよりますが、レイテンシーを縮めると入力と出力のタイムラグは45msec(0.045秒)程度まで縮められるので、ほぼ違和感なく歌うことが可能となっているのです。
さらに、その分析された線上の別の位置を選ぶと学習した歌声の持つ、さまざまな特徴を表現できるようになっています。つまり人の歌声の声質はずっと一定ではなく、刻々と変化するため、その変化具合を点で表しており、その変化が大きいと点の数も増え、それをつなぐ線の長さも伸びていく形です。
複数の人の声の中間のような声への変換も可能
ユニークなのは、複数の人の歌声を学習させると、それらすべてが画面上に表れてくるということ。わかりやすくするように、読み込ませた順に、点と線の色が変わってくるのですが、その配置が似た声の人であれば近く、違う声であれば遠くになるというのも面白いところ。
その上で画面上の任意の位置をマウスで指定すると、その位置の歌声が作り出されます。つまり線上であれば、学習した人そのものの歌声ですが、中間を指定すると、それぞれの点から線が引っ張り出されるような表示になるとともに、中間的な歌声が作り出されるUIになっているのです。
番組の中でも、カンルさんにいろいろお話を伺いましたが、その番組収録前にもインタビューを行ったので、その内容を紹介していきましょう。
開発者カンル・フアさんインタビュー
--Vocoflex、画期的なソフトの誕生だと思いますが、こういうソフトを作ろうというのはいつごろから考えていたのですか?
カンル:アイディア自体は2、3年前からありましたが、当時はこれを実現できる技術がなかったですし、そのためのデータも持っていませんでした。そもそも「歌とは何か」というのをAIが理解できなかったので、録音した歌声のどういう部分を学習すれば、そこに近づけられるのかということが見えなかったのです。しかし、AIの進化が急速に進むとともに、Synthesizer VやVOICEPEAKの開発・運用経験から私たちの持つノウハウも高まり、ようやく実現できるようになった、というところです。
 Vocoflexに関するインタビューに答えてくれた開発者でDreamtonicsの代表取締役のカンル・フアさん
Vocoflexに関するインタビューに答えてくれた開発者でDreamtonicsの代表取締役のカンル・フアさん
RVCをはじめとする既存のAIボイスチャンジャーとVocoflexの違いとは
--一方で、最近はRVCをはじめ、リアルタイムにAI音声変換をするボイスチャンジャーがいろいろと登場して話題になっています。それらとVocoflexは何が違うのですか?
カンル:確かに人のしゃべり声を真似るシステムはこの1年でいろいろと登場してきました。確かに使ってみると楽しいですが、アート的にはあまりできていないな…という思いもありました。ただ真似して終わりでは面白くないので、それをもっとクリエイティブなツールにしてみたいと、ボイスチャンジャーをより進化させたものとしてVocoflexを作りました。
--短い声を学習させて、その声に近づけるソフトという点では、先日Open AIが発表した「Voice Engine」というのが非常に近いように思います。
カンル:この先1年間、または数ヶ月以内にVocoflexと似たようなものが世の中に出ることは想定しており、それらが悪用されることになる前に、ちゃんと権利周りを整理した、ポジティブに使えるツールを出したい、と声優事務所や音楽制作関係の方々と慎重に話し合いを続けながら準備を進めてきました。そうした中で、Voice Engineが発表された格好です。Voice Engineは基本的には文字を入力するとしゃべるTTS=Text to Speachを目的にしたソフトであるのに対し、Vocoflexは歌声のためのソフトです。またVoice Engineとの大きな違いの一つは、リアルタイムで歌声を発声できる点であり、よりクリエイティブな使い方ができる、と考えています。そうした準備が整ってきたので、まずはウォーターマークや本人確認などの保護手段も実施したベータ版を出します。
従来のボイスチェンジャーとも根本的な仕組みが異なる
--声の周波数を分析し、フォルマントを取り出して……という手法は昔からありましたが、それとAIによるVocoflexのものは何が違うのですか?
カンル:周波数分布などは、数多くある歌声の特徴のごく一部分でしかないんです。たとえばブレスの成分がどのようにはいっているのか、高い声だとどのような歌い方をし、低い声だとどんな歌い方にかわるのか、1つ1つの発音をどうしているのかなど、数多くの要素があり、それを瞬時に分析して、プロットするのがこのVocoflexなのです。
--実際試してみると歌だけでなく、しゃべりに対しても自然に対応してくれますよね。
カンル:もちろんしゃべることにも対応できますが、しゃべりはあくまでもオマケ的な位置づけですね。歌のためにデザインしたソフトなので、歌のほうがしゃべりよりもずっと品質はよくなります。またVocoflexで行っているのは声質の変換です。しゃべる場合の人の声の特徴にはイントネーションというものがあります。東北の人、関東の人、関西の人でイントネーションが変わるし、中国人がしゃべった日本語もイントネーションが違い、そこがその人のしゃべり方の特徴ともなります。しかしイントネーションはピッチの変化であるため、歌声に最適化したVocoflexではそこはあえて変えていないのです。
--そのピッチという面では、男性と女性では大きく異なるわけですが、男性が女性の歌声にするとか逆に女性が男性の歌声にすることはできますか?
カンル:はい、そこは簡単にできるようにピッチシフト機能を内蔵させています。具体的には-18~+18の範囲で変えられるようにしているので、1オクターブ、つまり-12や+12を設定することで、容易に変換可能です。
学習させた声を2次元に点と線で表現。異なる人の声の間のモーフィングも可能
--学習させた声が点でつながった線で表現されるのはとってもユニークだと感じますが、この線がおかれる2次元において縦軸、横軸はどんな意味を持っているのですか?
カンル:縦軸、横軸に意味があるわけではないんです。単に声の違いを表現し視覚的にわかりやすく配置できるようにしたもので、パラメータの意味を言語化できるものではありません。また形、配置は自動的に決まるので、ユーザーはこの空間上で位置をマウスで指定して使う形になっています。女性が左、男性が右になる傾向は固定ではありません。特徴が近い声は近くに配置されます。一方、マウスで線と線の間の位置を指定すると、声質を示す各点から線が伸びていくのが分かると思います。ここには影と日なたがあって、日なたをもっと極端にしていく……といった使い方もできるようになっています。
--学習させる歌声の長さによって、点の数や線の長さが変わってくるように感じましたが、この学習させる歌声の長さによって品質が変わったりするのですか?
カンル:長いサンプルでも点(サンプルから切り出したパート)に変換されるため、10秒あれば十分で、それ以上あってもほとんど変わらないですね。一方、このVocoflexは、録音した歌声がなくても、性別やトーンを指定すると、ランダムに新しい歌声を生成することも可能になっているのも大きな特徴です。画像から色を取り出すイメージカラーピッカーのような見た目で、カラーコード指定することも可能なユニークなUIにしてあります。
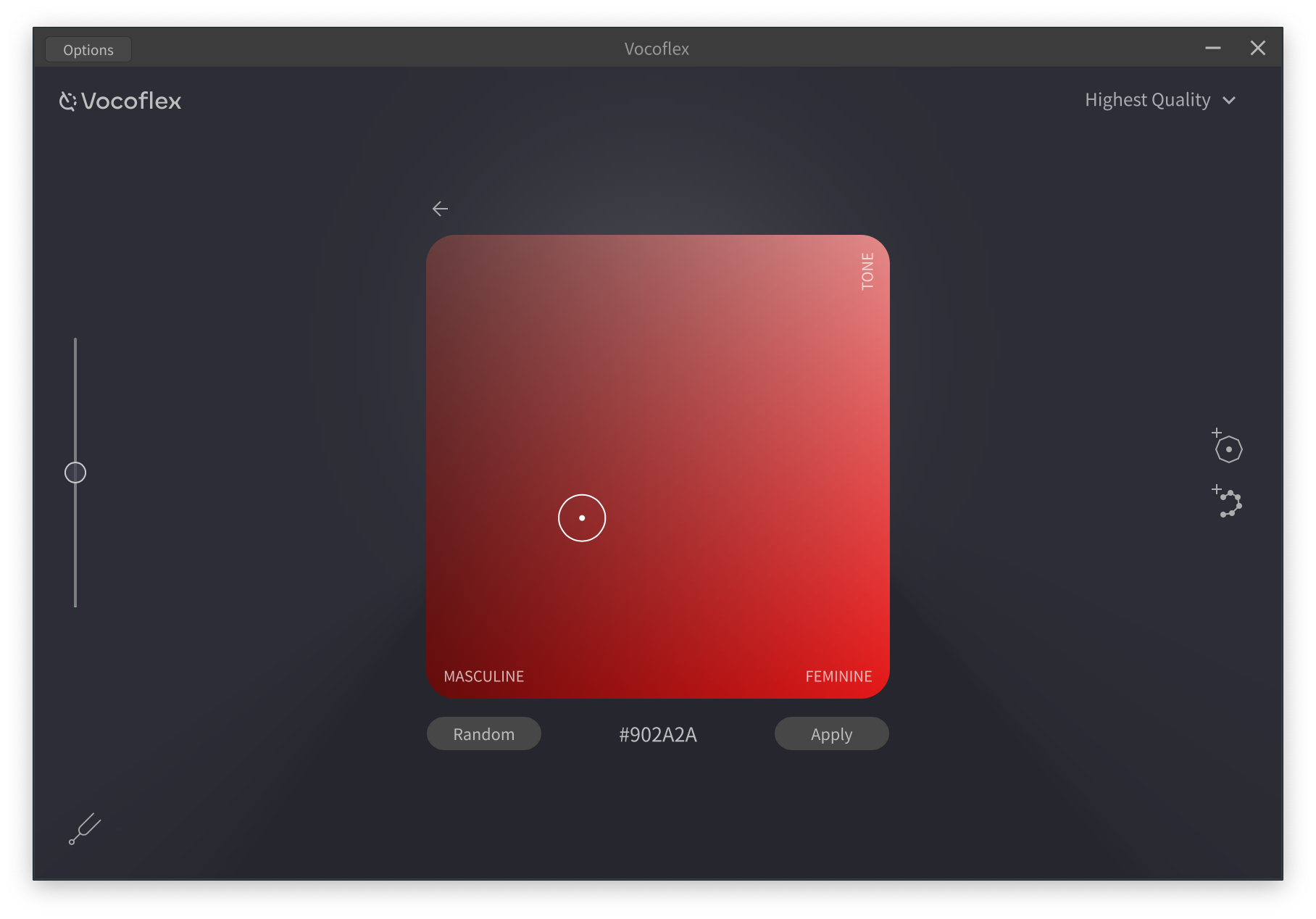 カラーピッカーのような画面を通じて歌声を生成することが可能
カラーピッカーのような画面を通じて歌声を生成することが可能
Syntheseizer VとVocoflexとの連携も可能
--ところでSynthesizer Vで合成した歌声に対してボイスチャンジャーを使って変換をしている人の作品を時々見かけますが、Vocoflexを使うと、よりキレイにできそうですが、そうなると歌声データベースが売れなくなる心配が出てくるのでは?
カンル:VocoflexはSynthesizer Vの可能性を広げる、相乗効果を持つツールだと考えています。確かに、Vocoflexを使うことで、さまざまな声色にすることが可能で、表現できる範囲は大きく広がります。でも、歌声データベースは単に声色が変わるだけではなく、元となる歌った人の歌い方そのものを表現できるツールなので、Vocoflexで置き換えられるものではありません。とはいえメインボーカル、バックコーラス、そのパートによってVocoflexでバリエーションを増やすといった使い方には非常に有効で、一人何役もこなしていくことができるという意味で、便利なツールとして使っていただけると思います。また、Dreamtonicsの歌声データベースの利用は可能ですが、他社の歌声データベースについては非対応の予定です。
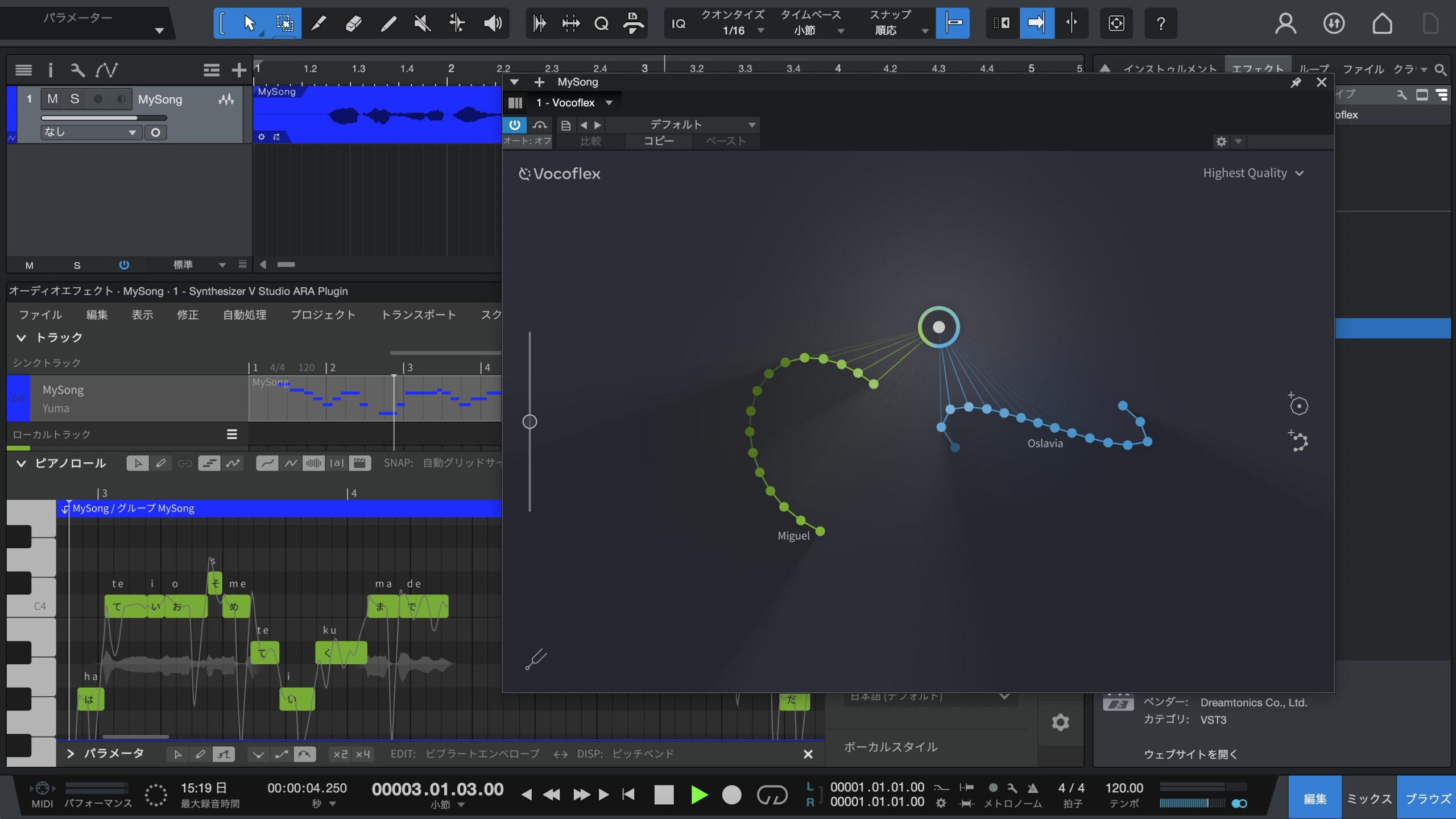 Synthesizer VとVocoflexを連携させて歌声を変換することもできる
Synthesizer VとVocoflexを連携させて歌声を変換することもできる
ウォーターマークや個人確認で権利保護や悪用防止対策も
--ここ最近のAIの技術進化は面白いですが、とくにボイスチェンジャーなどは犯罪に使われる可能性なども指摘されています。この点についてはどのように捉えていますか?
カンル:Vocoflexは歌声のためのシステムなので、しゃべるためのシステムと比較すると、犯罪に使われるといったことは少ないとは思うものの、その点に関しては我々も非常に危惧しており、声に関する権利者の保護なども含め、できる限り慎重に事を進めています。いろいろな対策を講じているのですが、まずは生成された歌声にはウォーターマーク(電子透かし)が付く形になっており、それがVocoflexを用いて作られたことがすぐにわかるようにしています。もちろんウォーターマークを外せないよう、技術を駆使しています。実際このウォーターマークにより、Dreamtonicsでは使用者を特定することができるため、使用許諾を得ていない音声ファイルのインポートを防ぐことができます。BGMとのミキシングや電話回線を介した非可逆圧縮など、さまざまな音声操作に対しても堅牢であり、波形編集ソフトやスペクトル編集ソフトなどで取り外すことも不可能です。
--そのウォーターマークによって音質が劣化したりする心配はないですか?またVocoflexで作ったということ以外に、誰が作ったデータであるかといったことも判別できるのですか?
カンル:音質にはほぼ影響がない形のウォーターマークにしています。防犯上、セキュリティ上の観点から、ウォーターマークに関する詳細については伏せさせていただきますが、万が一悪用された場合も、誰が行ったかなどを把握できるようなシステムにしています。
--ほかにも何か策を講じているのですか?
カンル:はい、今回Vocoflexをベータ版として公開しましたが、Synthesizer Vのように、誰にでも配布するというわけではなく、申請フォームに用途なども記載していただき、当社側で審査を行った上でお渡しするようにしています。また、今後販売することになった場合には、購入時に本人確認を行うことなども検討してるところです。
--かなり、ガチガチに固めているようですが、VocoflexはSynthesizer VやVOICEPEAKのように、一般に幅広く販売する形になるのでしょうか?
カンル:toBのみで展開する製品にするのか、toCも含めて広く販売するものにするのか、さらには価格設定をどうするかなども含め、まずは今回のベータ版に関してみなさんからのフィードバックをいただいた上で検討していきたいと思っています。ぜひ、みなさんから多くのご意見をいただければと思っています。
--ありがとうございました。


コメント