文字を入力して喋らせる音声合成は、ここ数年で大きく進化して、よりリアルな声で人間の喋り声と判別できないレベルになってきています。ただ、いくらリアルになったとはいえ、リアルタイムでアクションするのは困難であり、どうしてもノリの悪いやりとりになってしまいます。そうした中、注目されるのが自分の声を直接違うキャラクタの声に変換できるボイスチャンジャーです。そうしたボイスチェンジャーもハードウェアタイプのもの、ソフトウェアタイプのものなど、さまざまなものがある中、現時点における本命ともいえるのが、クリムゾンテクノロジーが出す変幻自在の声質変換ソフトであるVoidolです。
DTMステーションでも、これまで何度か取り上げてきましたが、この度、Voidol 3へとメジャーバージョンアップを図り、よりリアルに、そしてよりクリアな声に変換できるように進化しました。その一方で標準搭載のキャラクタが従来の6つから13へと増え、より多くの声を出すことが可能になったのも嬉しいポイントです。今回のバージョンアップでは、ユニークな工夫がされたことで、無理なくターゲットの声にしていくことができるようになったのですが、どんなボイスチェンジャーになったのか試してみたので、紹介してみましょう。
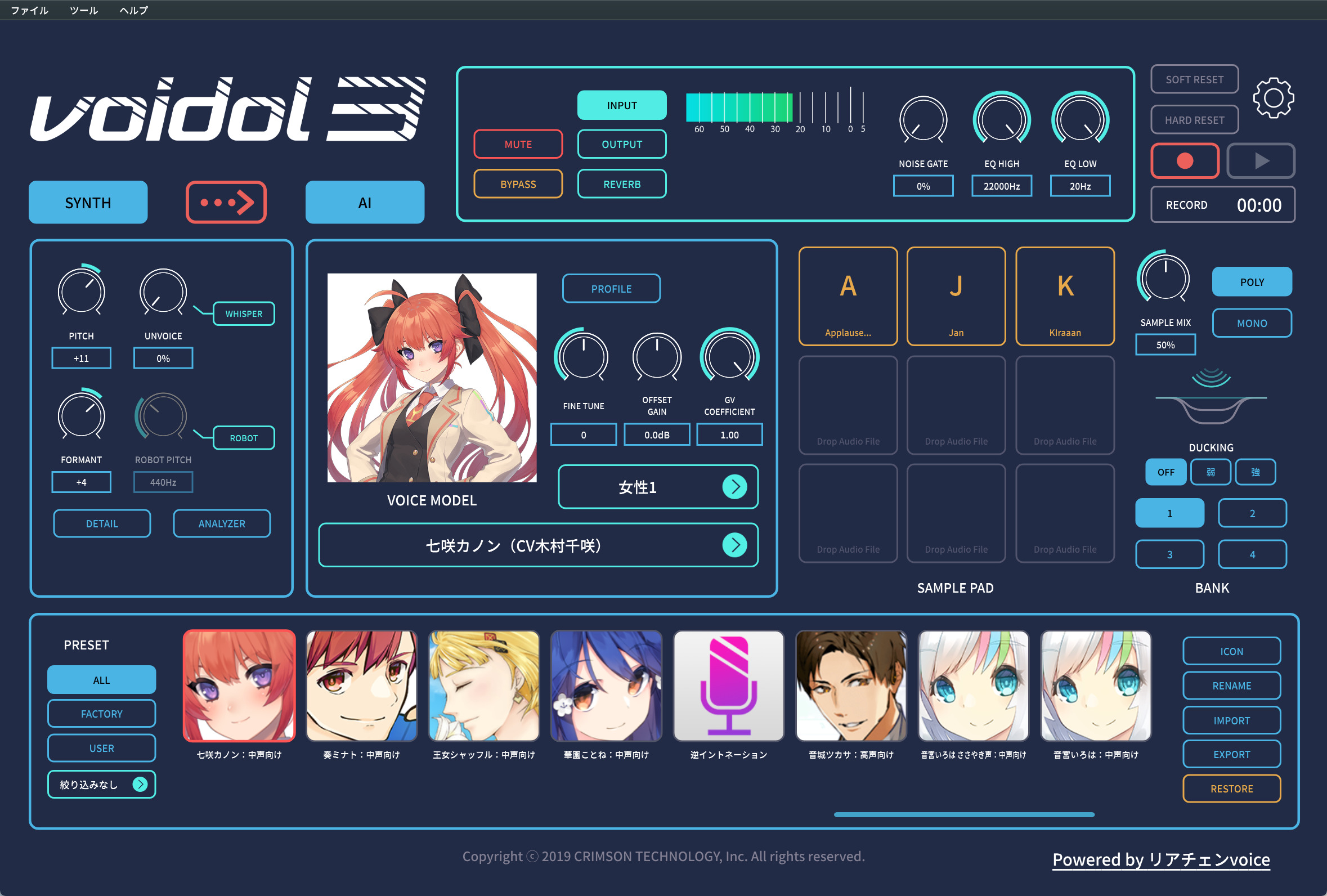
従来の不満点を解消し、普通に喋って変換できるVoidol 3
Voidolは、WindowsもしくはMacを利用して、自分の声をリアルタイムにキャラクタの声に変換するというボイスチェンジャー・アプリです。これまでも「VTuberに超強力兵器が誕生!リアルタイムに自分の声をキャラクタボイスに変換できるソフト、Voidolが発売開始!」、「VTuberのための悪魔のアイテム、Voidolに新キャラ12種類が追加。自分の声を佐藤聡美さんや小岩井ことりさんに変身!」、「Vtuberにも人気のAIボイスチェンジャーが新音声変換エンジンを追加し、Voidol 2へ。声は自在に作り込む時代に」……といった記事で取り上げてきました。
マイクから入力した声が、リアルタイムにキャラクタの声に変換され、レイテンシー(タイムラグ)が非常に小さいため、VtuberでVoidolを使っている人もかなり多いようです。ただ、これまでのVoidol 2のユーザーからはいろいろな不満点が出ていたのも事実です。その一つは音質面。確かにリアルタイムで変換はできるけれど、もう少し音質が向上できればいい…といった声も出ていました。また、選んだボイスモデルの特性に近づけるためにはある程度事前練習をする必要があり、男性が女性のキャラクタになる場合は、女性っぽい声で入力するなど、かなりコツがいるというか、人によってはなかなかうまく行かないケースがあったのです。
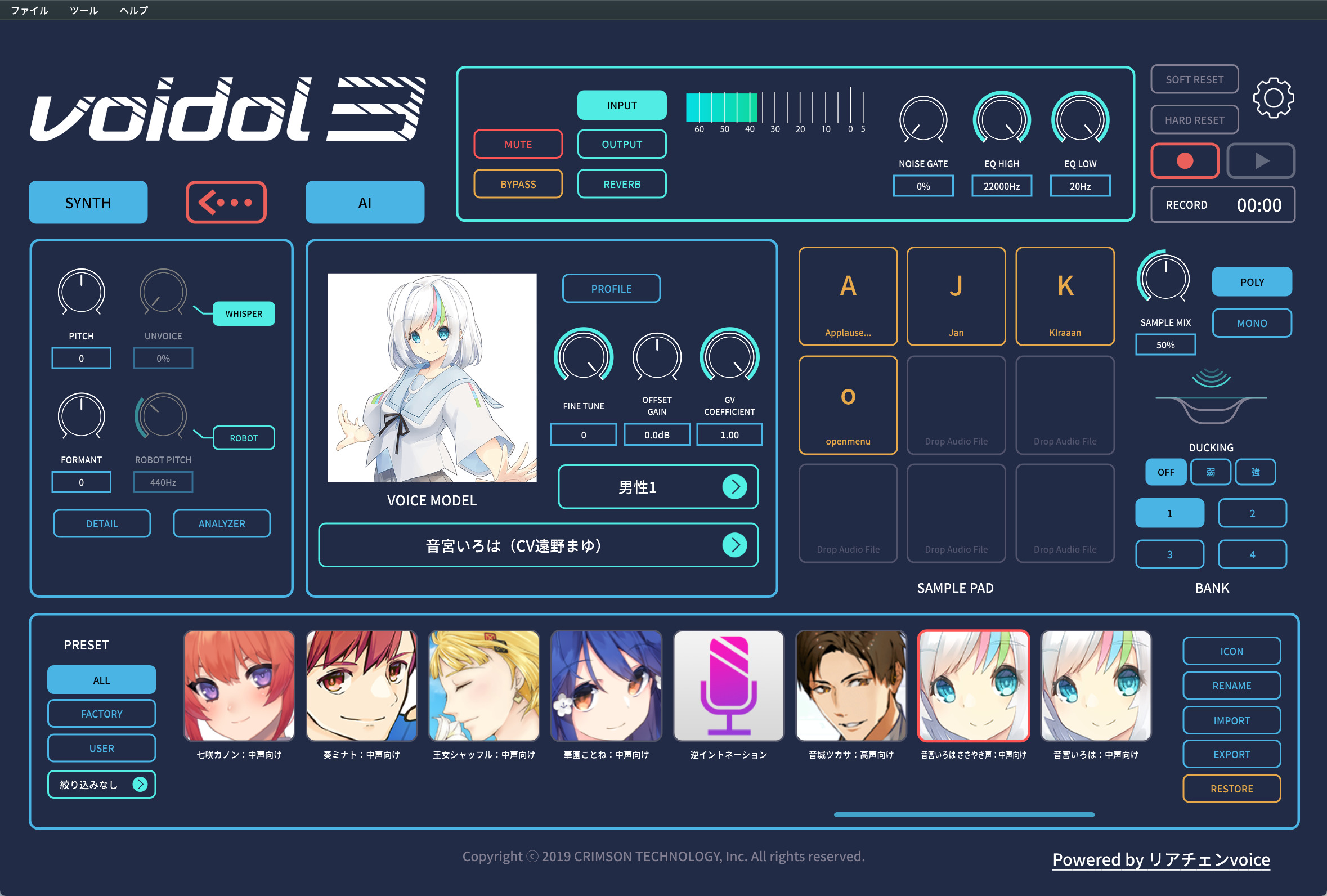
今回のVoidol 3では、そうした不満点を解消しているのが大きなポイント。とくに、入力音声を女性の声質に近づける必要がなくなった、という点は大きな進化点です。もちろん、喋り方自体は、喋る本人のものが反映されるから、演技自体は必要なのですが、高い声で喋べる必要性がなくなったので、すごく使いやすくなっています。このことは女性が男性キャラクタになりきる場合もまったく同様で、低い声でしゃべる必要はないのです。
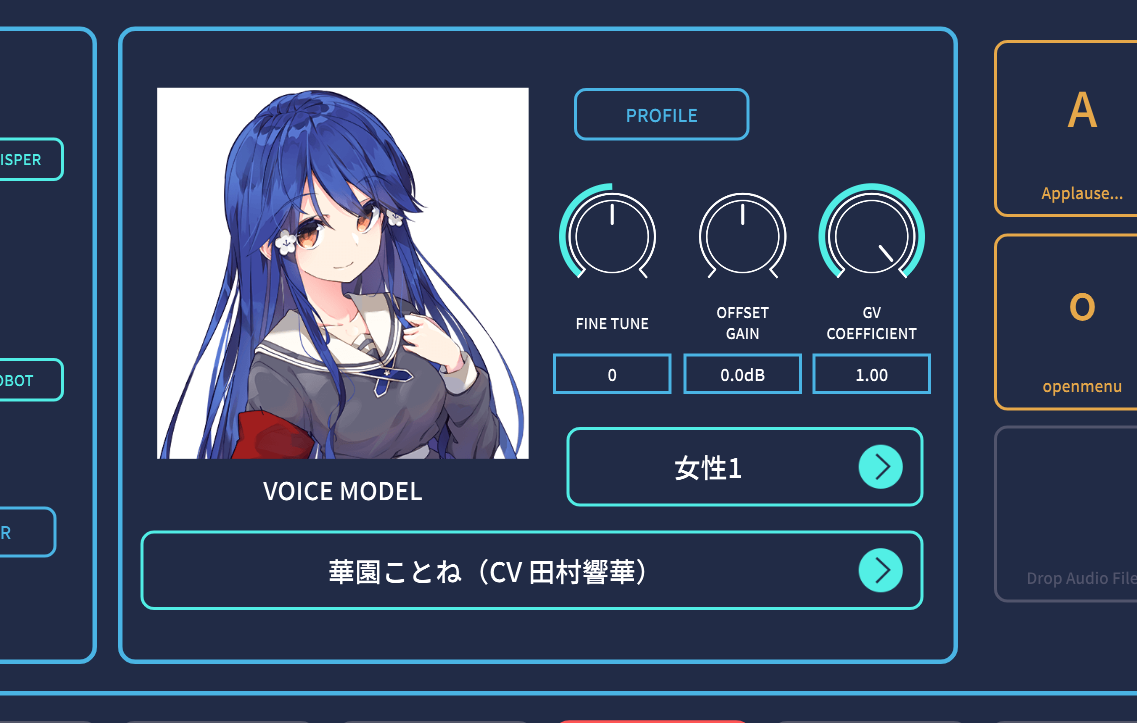
今回のVoidol 3になったことで増えたキャラクタの一つに、声優・女優の田村響華さんがCVを務める「華園ことね」があります。そう、DTMステーションPlus!の番組でお馴染みの田村響華さんです。そこで、試しにDTMステーションPlus!の冒頭のコーナー、「田村響華と今日からDTM♪」のタイトルコールを喋ってみたのがこちらです。
どうでしょう?響華さんと似てるのか…というと、そっくりではないかもしれませんが、それなりに雰囲気は出ているように思うのですが。また、前半が私の声そのまま、後半が変換結果なわけですが、普通に喋ったものが、普通に反映されているのが分かると思います。ちなみに、ホンモノのタイトルコールは、こちらですね。

AIエンジンの前処理としてSYNTHエンジンを利用する
では、このVoidol 3、どんな処理をして、自然な入力が可能になったのでしょうか?もともとVoidolの変換エンジンはAIを用いたものだったわけですが、Voidol 2になったとき、このAIエンジンとはまったく別に、シンセサイザ的に実現させる従来型のSYNTHエンジンも採用し、どちらでもAIモード、SYNTHモード切り替えて使えるようになっていました。
今回のVoidol 3では、その2つを同時に利用できるようにしており、AIエンジンに入れる前に、SYNTHエンジンで、ある程度女性っぽい高い声に変換した上で、AIエンジンに突っ込むという、2段階の構造にしているのです。その結果、無理なく変換ができるようになったんですね。また、そのこととはまったく別に、声質も向上しているのですが、その辺を紹介したビデオがあるので、こちらをご覧ください。

いかがでしょうか?東北ずん子の声はかなりいい線に行っているのでは…と思いました。
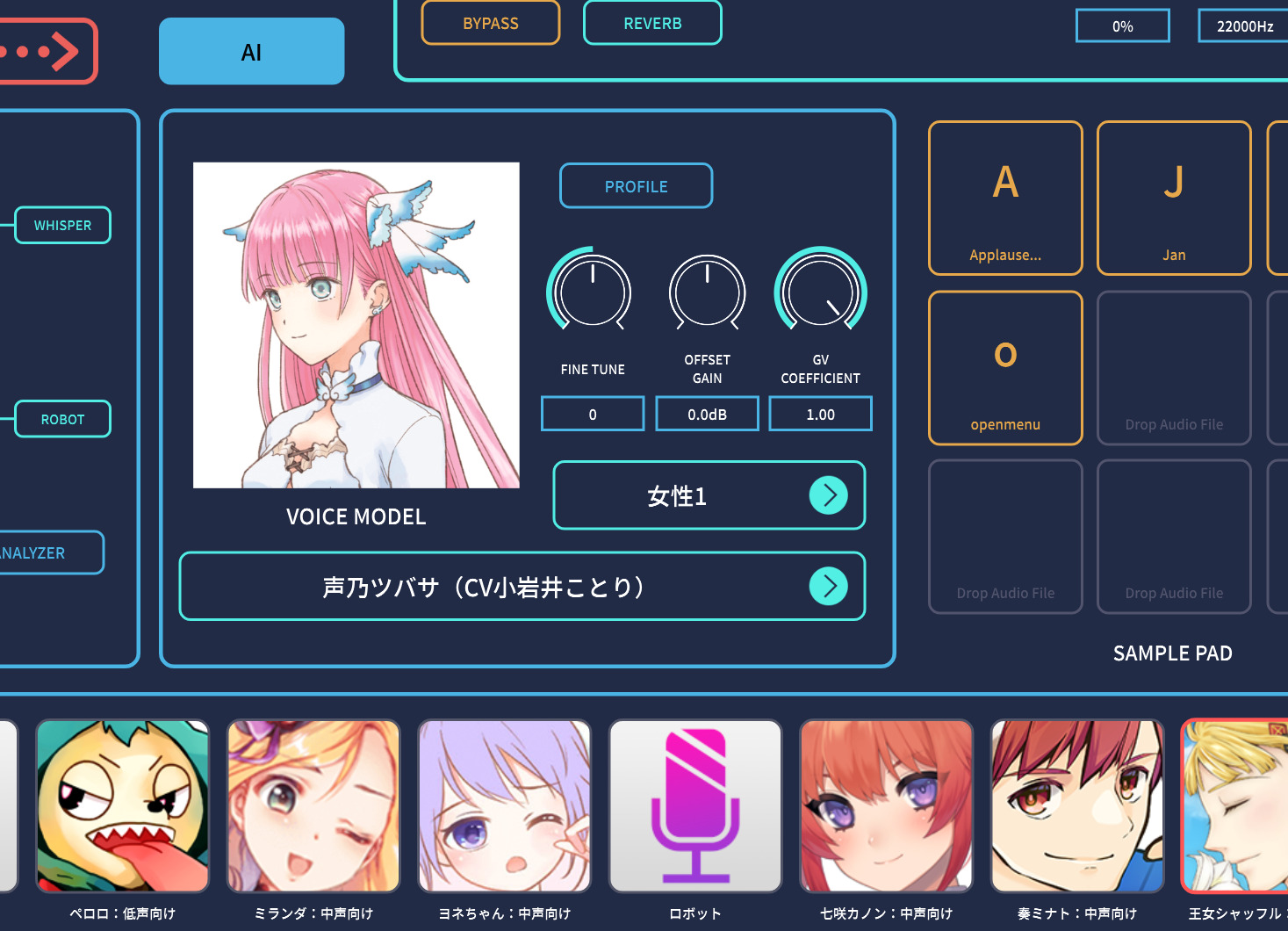
Voidol 3はシンセサイザのパラメータが前面に出てきたことで、ちょっと難しそうにも見えますが、基本的には画面下にあるキャラクタのアイコンをクリックするだけで、プリセットが設定されて、すぐに使えるようになっています。

また、シンセサイザのパラメータとはいえ、基本的にはPITCHで、声の高さを調整し、FORMANTで太い声やカワイイ声など声質を調整するだけでOK。変幻自在な声質変換ということもあって、吐息成分多めなウィスパーボイスにしたり、ピッチが固定されたロボットボイスにすることも可能になっています。
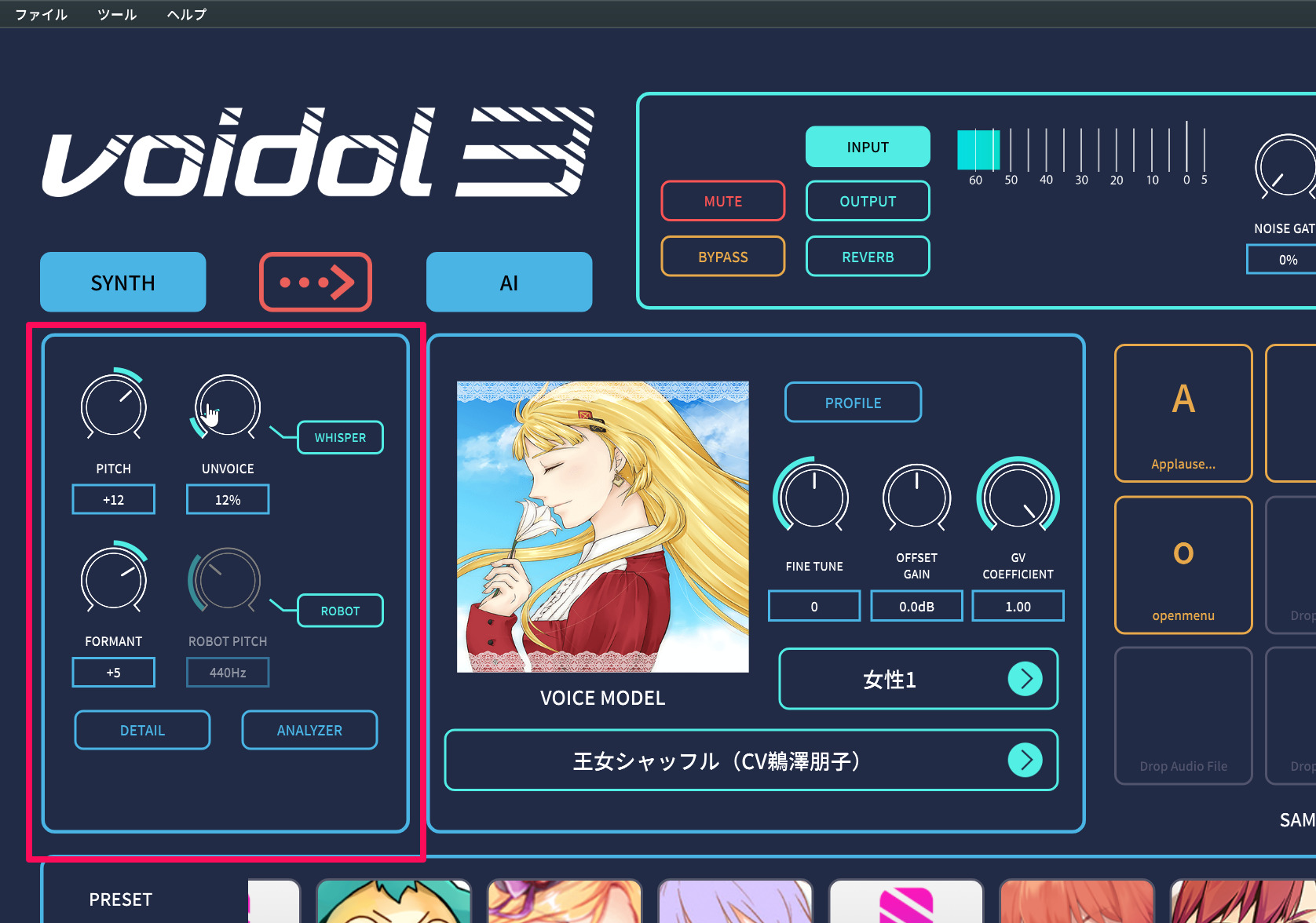
画面左の赤で囲った部分がシンセサイザエンジン
そうした設定の一方で、AIエンジン側でターゲットとなるキャラクタ=VOICE MODELを選択すればOK。簡単にボイスチェンジが可能になるのです。
あとはキャラクタを選択するだけで使える
また各種パラメーターをいじって、自分にピッタリな状態になったら、ユーザープリセットとして保存することも可能です。そうすれば、画面下のアイコンをクリックするだけで、最適な状態にすることができるので、とっても便利ですよ。
ちなみに、通常の使い方はSYNTHエンジンを経由させてAIエンジンへと繋ぎ込む形となりますが、SYNTHエンジンだけを使うとか、AIエンジンだけを使うということも可能。また、どれだけ意味があるかはわからないですが、AIエンジンを通した音をSYNTHエンジンへ送るという逆方向接続も可能になっています。これにより、キャラクタボイスをベースにロボットボイスにするとか、すごく吐息成分多めの声にする……といったエフェクト的な使い方も可能になります。
既存のボイスモデルもそのまま利用可能
なお、Voidol 2にあった、ポン出しボタンであるSAMPLE PADは従来よりも増えて9つ搭載されています。ここに歓声や拍手、ピンポーン!、ブブー…といった効果音を入れておくことで、ネット番組などの進行中やイベントでの利用中に活用できると思います。
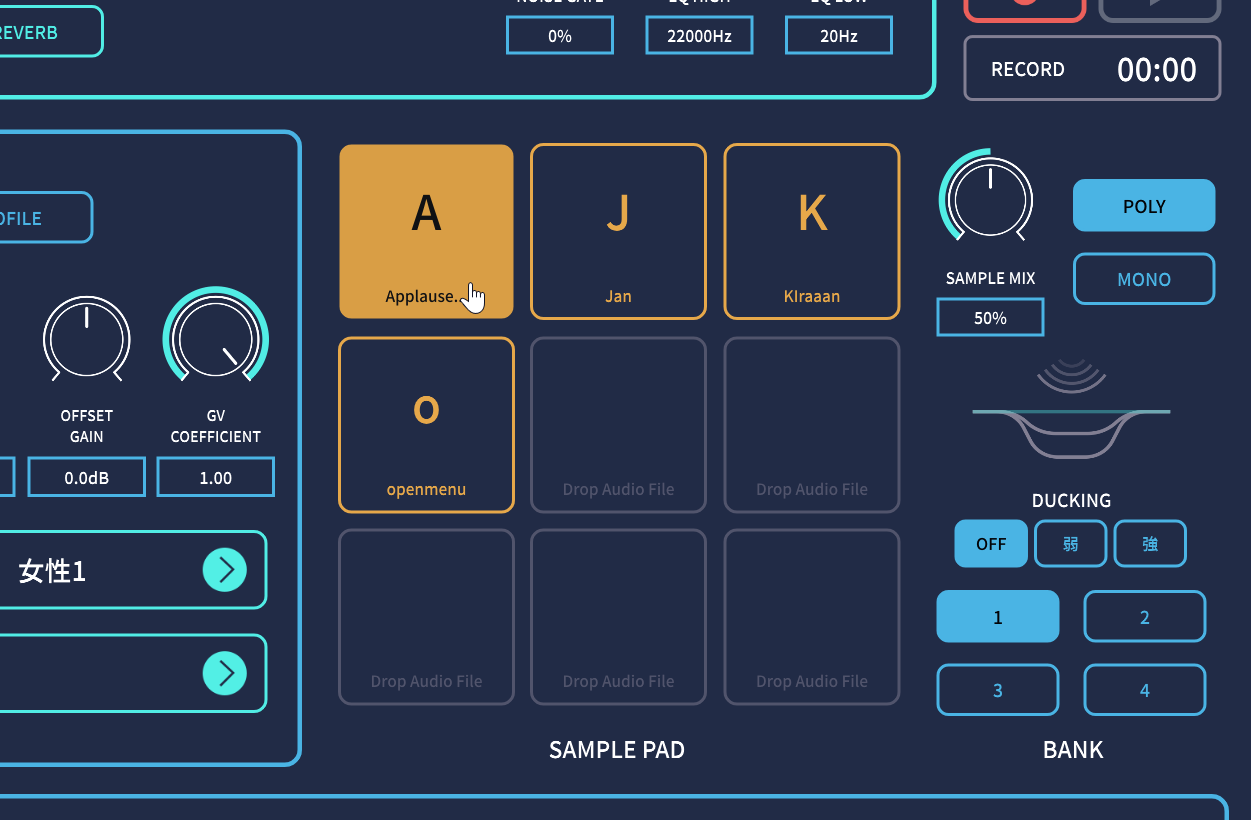
効果音などをポン出しできるボタンであるSAMPLE PADは9つ用意された
ところで、読者のみなさんの中にはすでに最初のバージョンであるVoidol、これまでのバージョンであるVoidol 2を持っている方も少なくないと思います。そうした既存ユーザーにはアップグレード版というものが用意されており、税抜通常価格が27,000円のところ、17,000円で購入することが可能です。
一方、単体のVoidolに加え、追加のボイスモデルを購入していた……という人もいると思います。そうした人は、その追加ボイスモデルをそのままVoidol 3で使うことが可能となっています。そう、基本的なAIエンジンは変わっていないので、そのまま利用できるのです。ただし、先ほどの田村響華さんがCVを務める華園ことねのように、Voidol 3に標準として搭載されたものについてはダブってしまうのが、ちょっぴり残念なところではあるのですが……。
ここでは詳細は割愛しますが、SYNTHエンジンをさらに細かく設定していくDETAIL機能、さらに入力された音声を細かく分析するANALYZERなどはVoidol 2のものをそのまま継承しているので、好きな人はこのあたりを存分に使いこなすのも面白いのではないでしょうか?
CPU負荷とレイテンシーについて ※2023.9.9追記
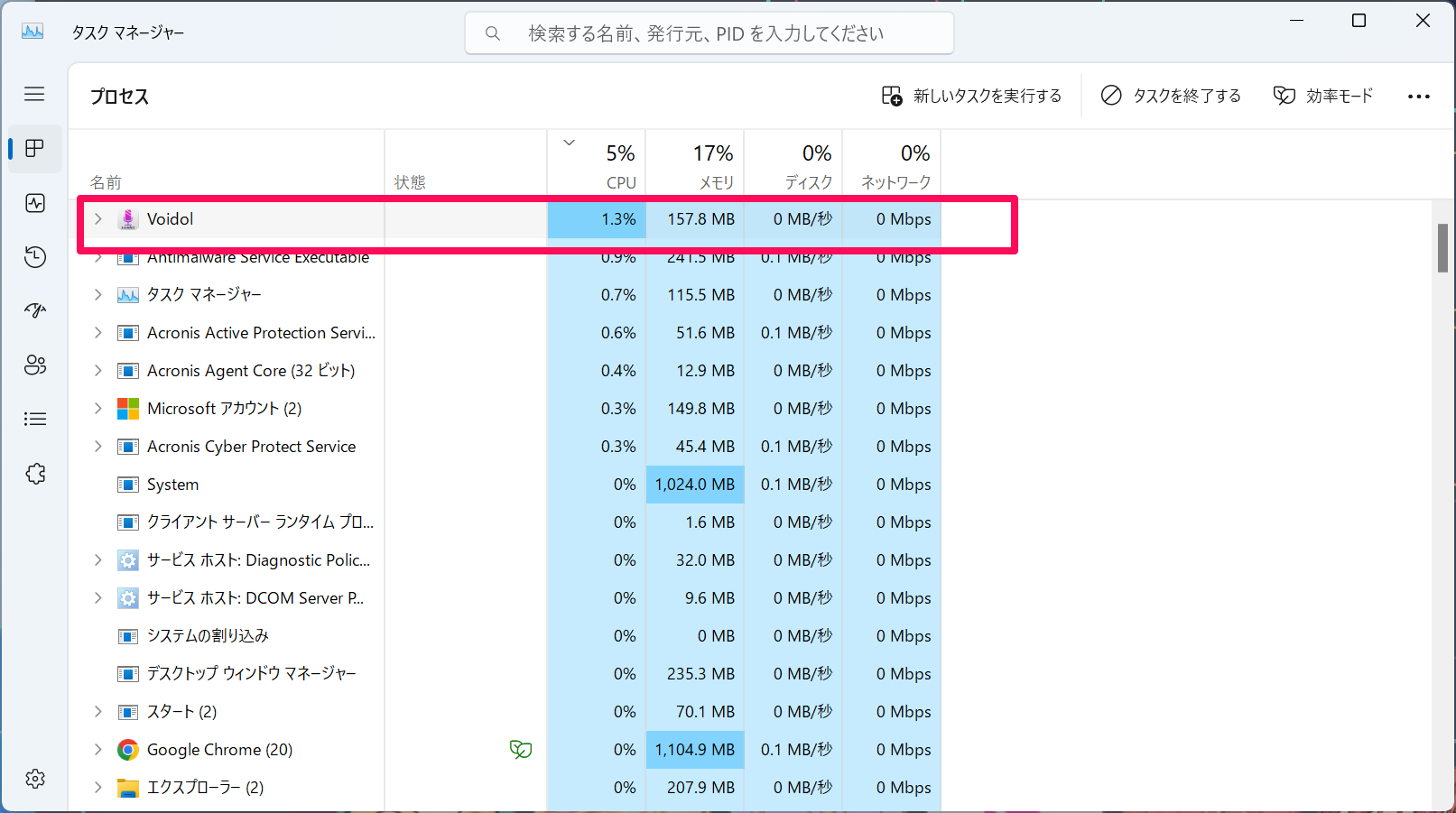
SNSでCPU負荷やレイテンシーについての記載がないが…といった指摘がありましたので、追記の形で報告いたします。一言でいうと、負荷は非常に軽く、レイテンシーもほぼない、という状況ですが、もう少し具体的に紹介しましょう。使っているのはWindows 11で12世代Core i-9 12900Hという機材。ここにオーディオインターフェイスを接続し、サンプリングレート48kHz、バッファサイズ32sampleで入出力を設定して試してみたところ、Voidol 3単体のCPU使用率が1~2%程度でした。また、ヘッドホンでモニターして聴く限り、ほぼリアルタイムです。微妙にショートディレイが入っている感じなので、実際は20msec程度のレイテンシーはありそうですが、モニターしながらでも違和感はまったくなく使えます。
【関連情報】
Voidol 3製品情報