ここ1、2年、AIの進化は劇的でChatGPTや画像生成AIなど、革命的アプリケーションが次々と生まれています。そうしたAIの革命的アプリケーションのもうひとつが、歌声合成ソフトのSynthesizer Vであることは間違いありません。すでに人間の歌声と区別がつかないレベルに来ており、6月にリリースされた1.9.0ではラップにも対応するなど、その進化は留まることを知りません。
その1.9.0でのラップ機能や多国語対応などについては、先日、開発者であるDreamtonicsの代表取締役、Kanru Hua(カンル・フア)さんのインタビューで詳細を紹介したばかりです。が、本日8月2日、またDreamtonicsから爆弾のような発表がされました。それが次期バージョン1.10の発表であり、Synthesizer Vの歌声がさらに大きく強化される、というのです。そこには人の感性を利用している、という背景があり、人間とAIの共存があるからこそ、実現できているから、なのだとか…。でも、そんなことが本当に可能なのか、どうやって強化されるのか、気になることがいっぱい。そんなことをゆっくり、考える余裕もなく、本日からそのβテスト版である1.10.0 Beta1が公開になっています。1.9の次は、いよいよ2.0で、有料でのバージョンアップだろう…と思っていたら、まさかの1.10であり、この革命的新バージョンも既存のSynthesizer V Studio Proのユーザーなら誰でも無料でβ版を入手でき、その後製品版登場時も無料でアップデートが可能となっているのです。Synthesizer Vはどこに向かっているのか、さらに強化とはどういう意味なのか
実は前回の1.9のインタビューをした際、すでに1.10.0 Beta1もほぼ完成間近となっており、1.9の話が終わったときに「実は…」ということで、1.10の話もカンルさんから伺っていました。が、その時点では、まだ未発表だったこともあり、先日の記事「最新AI技術でついにラップも実現、Synthesizer Vはどこまで進化していくのか?」では1.10については一切触れずにいました。
しかし、本日正式にDreamtonicsおよびAHSから1.10について発表されたので、改めてカンルさんのインタビュー記事を掲載していきましょう。
RLHFに対応したSynthesizer V 1.10.0とは
--1.9.0が出たばかりなので、次はまだずっと先だろう……と思っていたのに、もう次バージョンなんですね。
カンル:はい、さらにスゴイものを作りました。でも、1.10の話をする前に、まず今までの経緯を振り返ってみましょう。Synthesizer Vは2020年6月に製品版としてリリース後、2020年10月にSynthesizer V AIとしてAIのエンジンを搭載しました。このAIを出したときから人間に近づいてこうという目標の元、さまざまなアプローチで人間の歌声に近づけていきました。そしてちょうど1年前、2022年7月に1.7.0を出した際、HDVM=High Dynamics Voice Modelという技術を実装させました。それが、AIリテイク機能です。

--1.7.0のリリース時に「Synthesizer Vの歌声合成は次の次元へ。調声は不要、AIリテイク機能で好みの歌い方を選べる時代に」という記事でインタビューさせてもらった話ですね。
カンル:人間が歌う場合、毎回同じではなく、上手いときもあれば、下手なときもある。また同じ上手い歌い方だとしても、強弱の変化があるので、同じ歌い方ではありません。だから平均をとった歌い方をさせると、人間っぽさがなくなってしまうのです。その問題に気づいてHDVMを取り入れたのですが、安定性に欠ける…という問題がありました。そこで、画像生成AIなどに使われているDPM(Diffusion Probabilistic Model:拡散確率モデル) という技術を取り入れたのが1.8です。さらに改良を加えた1.8.1でさらに上手に歌えるようになりました。ここで学んだことが2つありました。1つは「開発者がうまいと思うものと、ユーザーの認識は違う」ということ。だらかこそ、ユーザーフィードバックは絶対に必要と感じました。もう一つわかったのは、「もしかして、みんなが欲しいのは、本当の意味で自然な歌声ではないのではないか」ということです。
--本当の意味での自然ではないものを、ユーザーが求めている!?
カンル:「とっても自然な人間的な歌い方」ということと「歌が上手い」というのは同じではない、ということです。実際私たちが普段聴いている音楽も実際には自然ではありません。なぜかというと、レコーディングスタジオでも、ほとんどの場合ワ
「人間らしく自然に歌う」と「上手な歌い方」は別モノなのでは!?
--確かに、現代の音楽制作は、本当の意味での人間の自然な歌とは違うのかもしれません。
カンル:これまで人間の真似をしよう、人間そっくりにしよう……といろいろな手法を取り入れてきて、かなり人間に近いところまでは来ました。でも、無限に人間に近づけていくことはできても、人間を超えることはできません。それどころか、これ以上、人間に近づけるとかえって下手に聴こえる面が出てきてしまうことに気づいたのです。そこで、今回の1.10ではその問題を乗り越えるチャレンジをしてみました。
--どういうことですか?最初からMelodyneをかけたような歌声にしてしまう……とか?でも、それでは機械っぽくなってしまいそうだし……。
カンル:さすがに、それだと人間っぽくはならないでしょう。いろいろな歌い方の中で、うまいところだけを見つけ出して学習させるという方法もありそうですが、これもデータ量が多すぎて効率が悪くなってしまいます。そこで、RLHF(Reinforcement Learning from Human Feedback:人間のフィードバックからの強化学習)という手法を歌声合成に使ってみたのです。

--RLHF?強化学習?……よく分からないのでもう少し教えていただけますか?
カンル:たとえばChatGPTが出してきた答えに対して、「いい」とか「ダメ」とかフィードバックしていくことで、正しいいことを学習していきます。それをRLHFと呼んでいるんです。今までの機械学習だと、どんどん人間に近づけることはできても、限界はあるので、そこを超えて行こうと考えたのです。
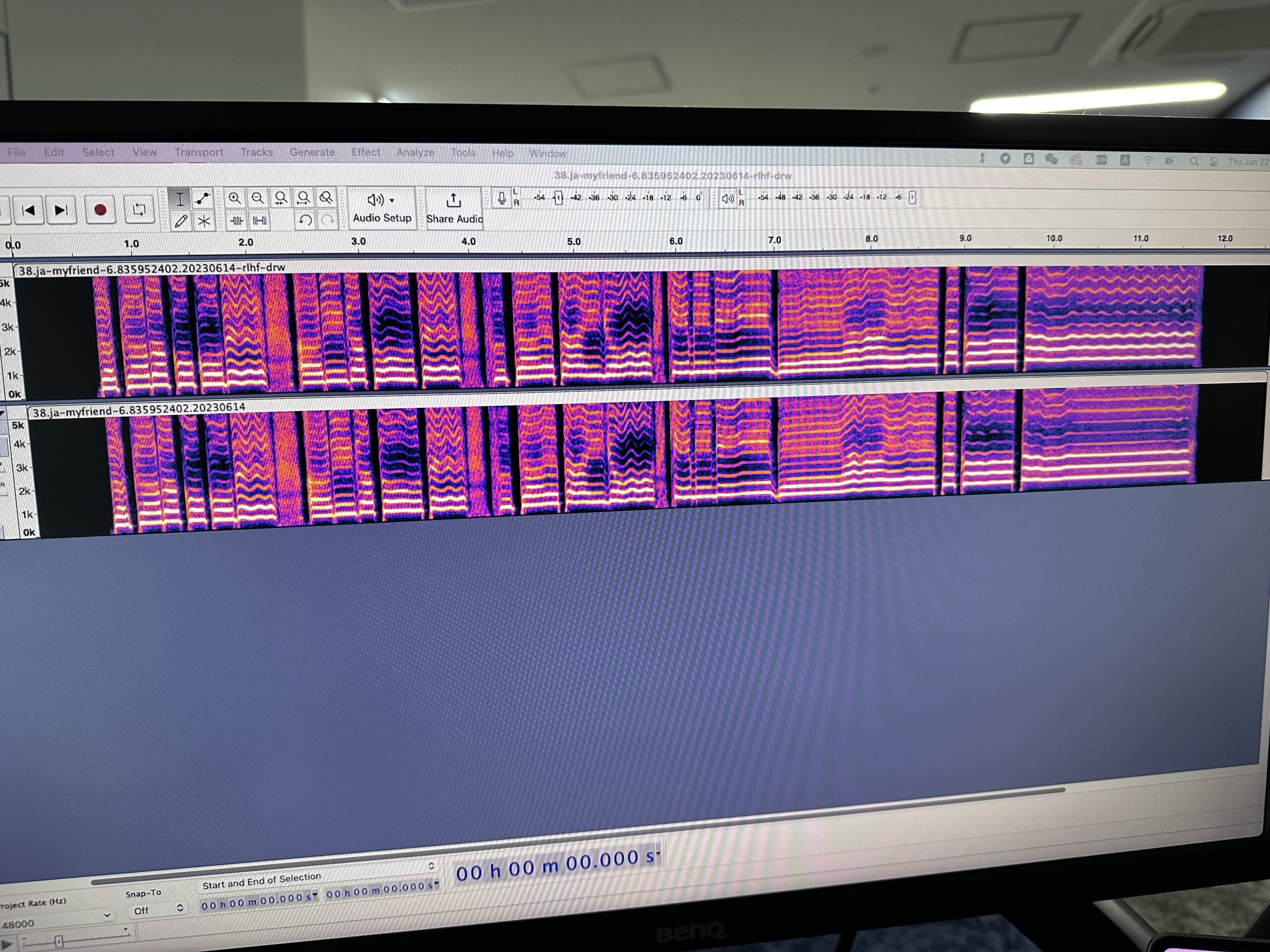
--具体的にはどうするんですか?
カンル:AIリテイクをした結果から、ユーザーはどれがいいのかを選択しているので、それを強化学習していくことわけです。RLHFによって、よりよい結果にしていくわけですが、そこも幅を調整できるようにしています。もちろん、ユーザーの同意をしてもらった上で、選択結果をフィードバックできるようにしようと思っています。
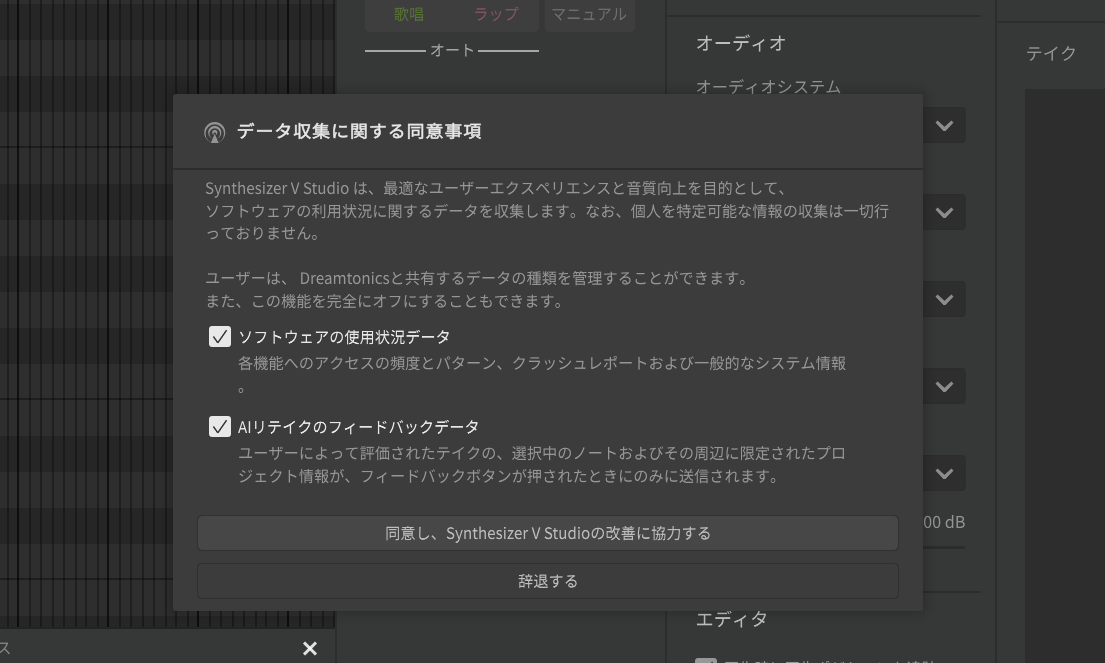
またプロジェクト全体ではなく、AIリテイクをかけた部分だけをフィードバックできるようにしようとしているのです。これによって、さらに歌声が強化され上手に歌うようになる……と
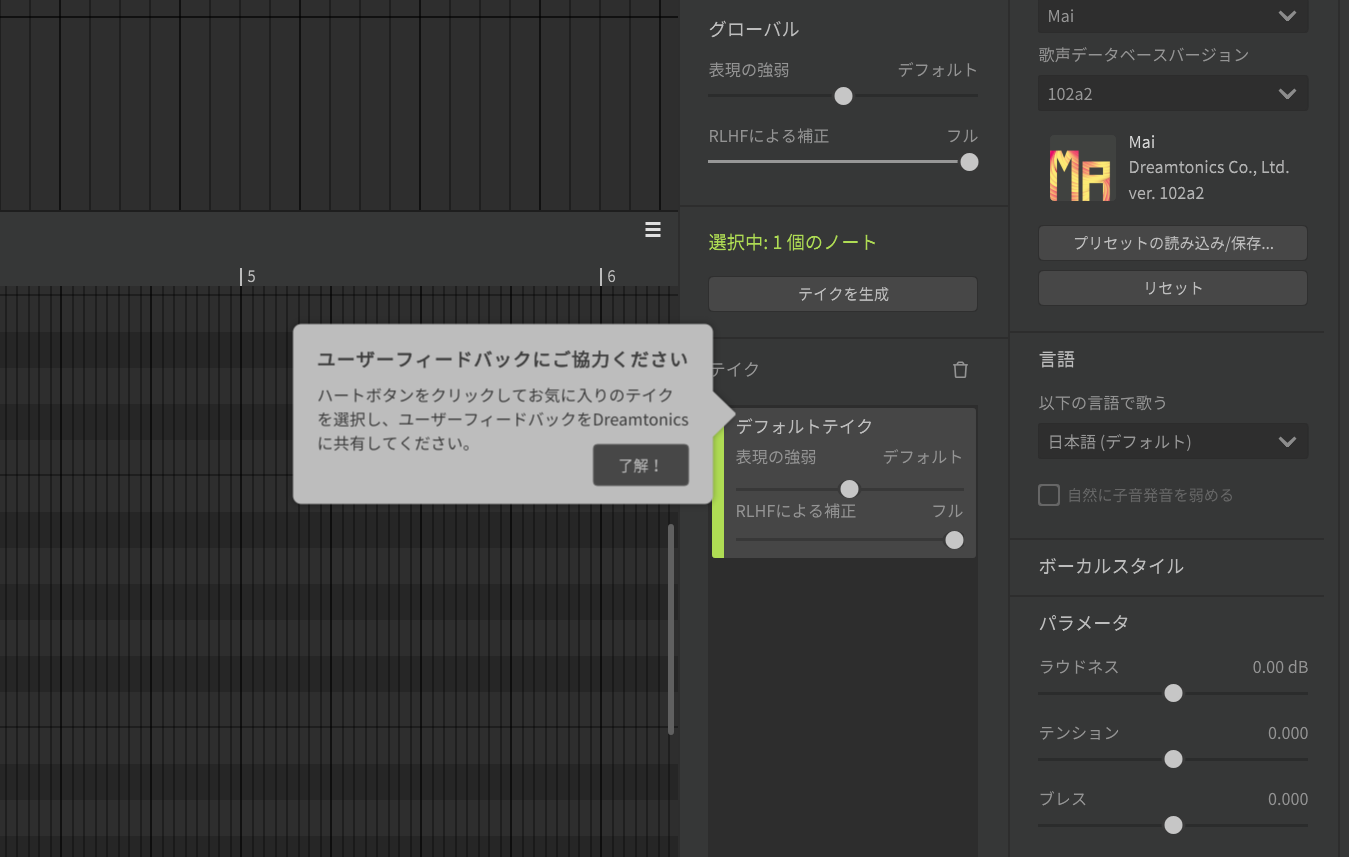
RLHF機能の実際の使い方
--具体的にはどのように使うのですか?
カンル:まず今回のSynthesizer V 1.10.0にともなってアップデートされた歌声データベースを使うと、AIリテイクの中に、新たにグローバルのいう項目が現れます。これは全体に対して影響することを意味するものですが、ここに「RLHFによる補正」というパラメータが出てきます。これがオフだと従来と変わりませんが、このパラメータを上げていくことで、強化学習された結果が反映されていきます。また、AIリテイクによる各テイクごとにRLHFによる補正を上げ下げすることも可能になっています。このRLHFによってビブラートやしゃくりあげなど、ピッチの表現力がかなりよくなると思います。もっとも、1.10.0においてはRLHFが効くのはピッチのみで、声色については今後対応する形になります。
--ユーザーがフィードバックするのはどのようにするのですか?
カンル:それは、AIリテイクの各テイクごとにあるハートアイコンのお気に入りを利用します。従来は、単純に気に入ったものを自分で判断しやすいようにハートアイコンを用意していましたが、今回はそれがデータとしてサーバーへ送られ、強化学習に使われていくのです。
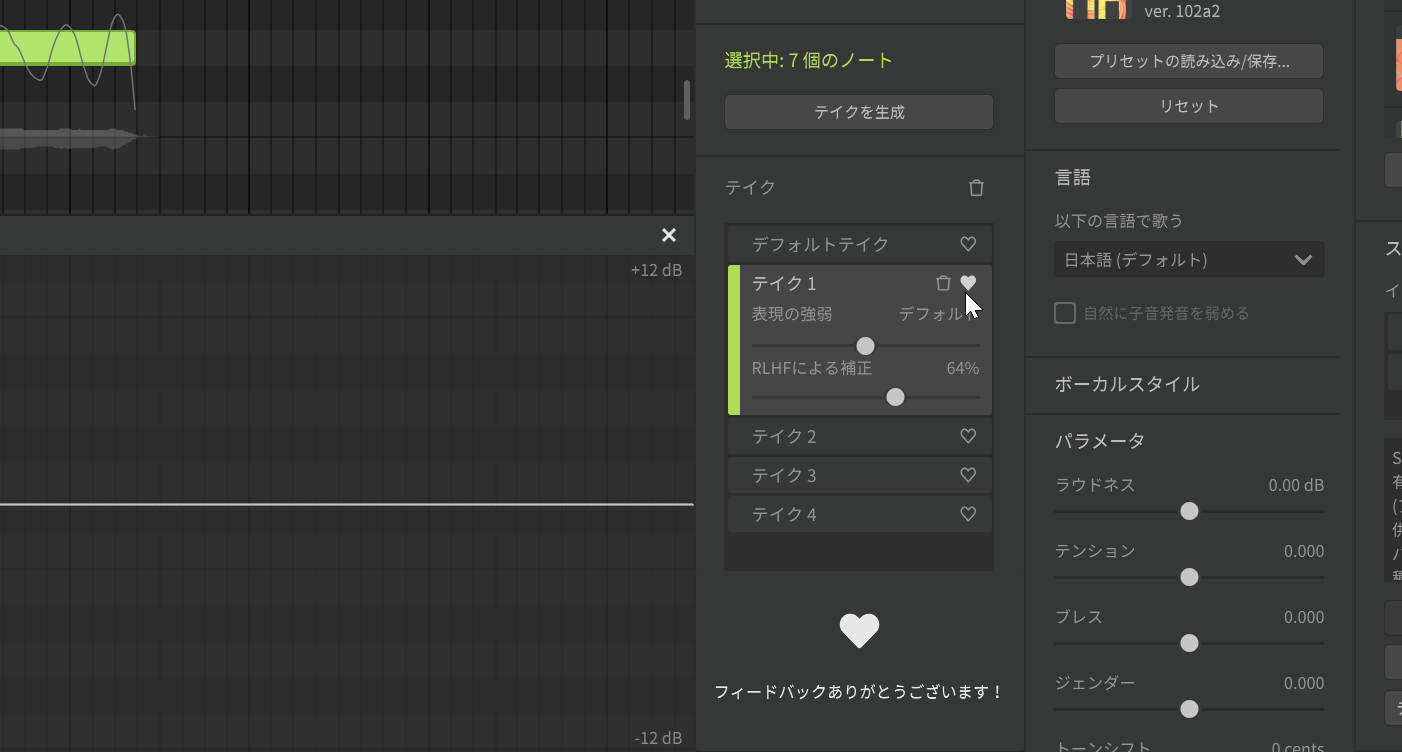
--このハートマークをクリックすることで、強化学習されていくわけですね。その結果は随時多くのユーザーに反映されていくのですか?
カンル:この強化学習の結果は、その次のデータベースのアップデートで反映されるので、どんどん変わっていくというわけではないです。ちなみに、今回の1.10.0 Beta1とともにリリースされたデータベースは、社内で1か月間評価した結果が反映されたデータとなっています。今後多くのユーザーのみなさんがフィードバックしてくださることによって、さらにいいものになっていくはずです。今後はピッチだけでなく、声色もラップも改善したモデルになっていきます。
トラックのカラー設定や、歌詞入力機能をよりスムーズに
--今回、そのRLHF以外にも変わったところはありますか?
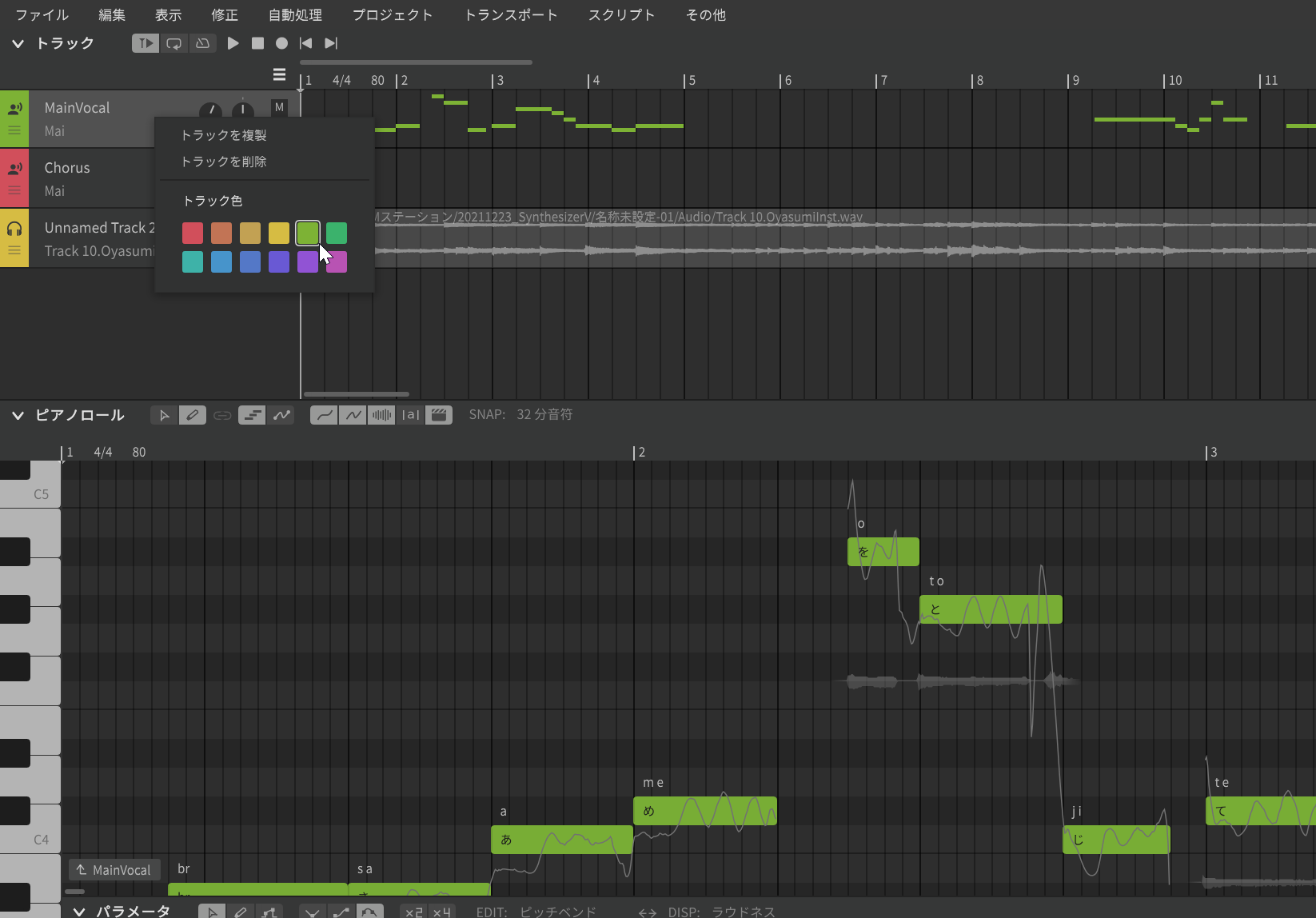
カンル:はい。ひとつは、トラックの色をユーザーが選択できるようにしました。従来はトラックを新たに作成すると自動的にトラックの色が決まっていましたが、トラックの頭の部分を右クリックすることで、パレットが現れ、この中から好きな色を選択できるようになりました。
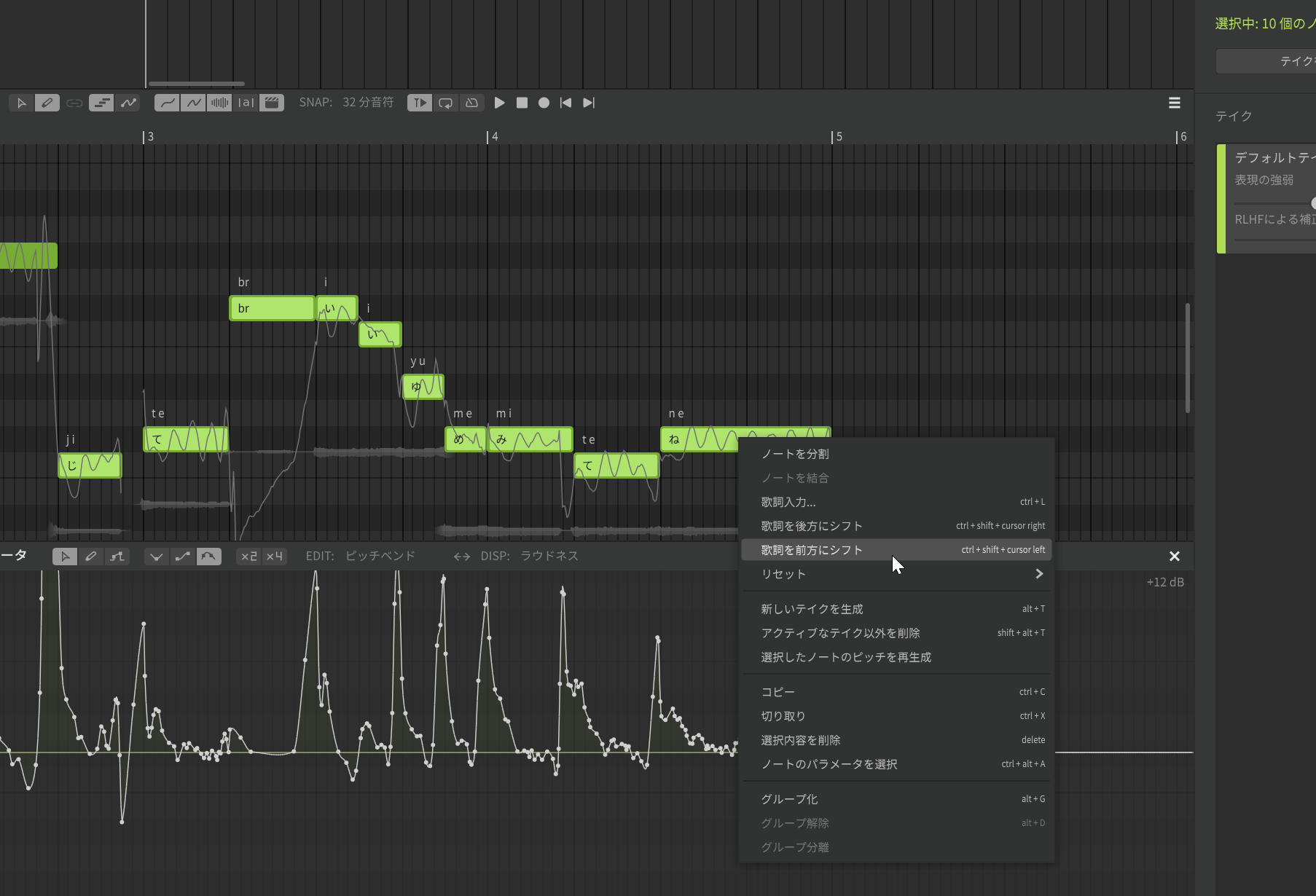
もうひとつは、歌詞の流し込みに関する機能です。これまでも歌詞の流し込み機能はありましたが、場合によっては、1つずつ右にズラしたいとか、左にズラしたい、ということがあると思います。それに対応するため「歌詞を後方にシフト」、「歌詞を前方にシフト」というものを用意したので、ぜひご利用ください。
--それにしても、何かスゴイところまで来てしまった……という気がしますが、今後Synthesizer Vはどう発展していくのですか?
カンル:そこは、私もまだ分かりません。まずは、何が上手な歌い方なのかを学習させながら、さらなるステップを実現させていければと思っています。もちろん、、Synthesizer Vは人間の役割を奪うために存在するものではありません。創造性はあくまでも人間にしかないものであり、その創造性をより発揮できるようにお手伝いをするのがSynthesizer Vです。ぜひ、そうした役に立つツールとして育てていきたいと思っています。
--今後の展開が楽しみです。ありがとうございました。
【関連情報】
Synthesizer Vシリーズ公式ホームページ(AHS)
Synthesizer V情報(Dreamtonics)
Synthesizer V Studio 1.10.0 Beta情報(AHS)
Synthesizer V Studio 1.10.0 Beta1情報(Dreamtonics)
【価格チェック&購入】
◎Amazon ⇒ Synthesizer V Studio Pro(パッケージ版)
◎Amazon ⇒ Synthesizer V Studio Pro スターターパック(パッケージ版)